在 Amazon EKS 上运行(带自动扩缩容)
由于 Amazon EKS 是 Kubernetes 集群的一个特定实例,因此在 Amazon EKS 上操作 HivePlus 与在通用 Kubernetes 集群上操作几乎相同。本页面解释特定于 Amazon EKS 的额外步骤,这些步骤与 HivePlus 的任何组件没有直接关系。有关一般说明,请参阅在 Kubernetes 上的指南。
安装 HivePlus 后,进入 eks 目录。
cd eks/
本页面的示例使用 eksctl 版本 0.207.0 和 kubectl 版本 1.23。请确保您的 kubectl 版本与 eksctl 的版本兼容。
概述
在 Amazon EKS 上运行 HivePlus 之前,用户应了解以下主题:
- 创建和更新 IAM 策略
- 使用命令
eksctl配置 EKS 集群 - (可选)创建 EFS 文件系统并通过 PersistentVolume 挂载
- 配置 LoadBalancer
创建 EFS 文件系统是可选的,因为 HivePlus 可以使用 S3 而不是 PersistentVolume 来存储临时数据。
用户可以在 AWS 控制台上或通过执行 AWS CLI 创建新资源(如 IAM 策略)。
用于访问 S3 桶的 IAM 策略
创建一个 JSON 文件(例如 MR3AccessS3.json),用于 IAM 策略,该策略允许每个 Pod 访问用于存储仓库和输入数据集的 S3 桶。如果使用 S3 存储临时数据,请扩展策略以允许每个 Pod 访问相应的 S3 桶(通常称为"scratch directory")。要限制允许 Pod 执行的操作用于限制 Pod 的操作集,请根据需要调整 Action 字段。
vi MR3AccessS3.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"s3:*"
],
"Resource": [
"arn:aws:s3:::hivemr3-warehouse-dir",
"arn:aws:s3:::hivemr3-warehouse-dir/*",
"arn:aws:s3:::hivemr3-scratch-dir",
"arn:aws:s3:::hivemr3-scratch-dir/*",
"arn:aws:s3:::hivemr3-partitioned-2-orc",
"arn:aws:s3:::hivemr3-partitioned-2-orc/*",
"arn:aws:s3:::hivemr3-partitioned-1000-orc",
"arn:aws:s3:::hivemr3-partitioned-1000-orc/*"
]
}
]
}
创建一个 IAM 策略并获取其 ARN(Amazon Resource Name)。在我们的示例中,IAM 策略被命名为 MR3AccessS3。
S3_ARN=$(aws iam create-policy --policy-name MR3AccessS3 --policy-document file://MR3AccessS3.json --query 'Policy.Arn' --output text)
echo "$S3_ARN"
arn:aws:iam::123456789012:policy/MR3AccessS3
用于自动扩缩容的 IAM 策略
要启用自动扩缩容,请创建 IAM 策略 EKSAutoScalingWorkerPolicy 并获取其 ARN。
vi EKSAutoScalingWorkerPolicy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"autoscaling:DescribeAutoScalingGroups",
"autoscaling:DescribeAutoScalingInstances",
"autoscaling:DescribeLaunchConfigurations",
"autoscaling:DescribeTags",
"ec2:DescribeInstanceTypes",
"ec2:DescribeLaunchTemplateVersions"
],
"Resource": ["*"]
},
{
"Effect": "Allow",
"Action": [
"autoscaling:SetDesiredCapacity",
"autoscaling:TerminateInstanceInAutoScalingGroup",
"ec2:DescribeInstanceTypes",
"eks:DescribeNodegroup"
],
"Resource": ["*"]
}
]
}
AUTOSCALING_ARN=$(aws iam create-policy --policy-name EKSAutoScalingWorkerPolicy --policy-document file://EKSAutoScalingWorkerPolicy.json --query 'Policy.Arn' --output text)
echo "$AUTOSCALING_ARN"
arn:aws:iam::123456789012:policy/EKSAutoScalingWorkerPolicy
使用实例存储
MR3 的 ContainerWorkers 将中间数据(如 TaskAttempts 的输出或通过 shuffle handlers 获取的 TaskAttempts 输入)写入本地磁盘。对于在 Kubernetes 上运行 HivePlus,有三种方法为 ContainerWorker Pod 模拟本地磁盘:
- 使用配置键
mr3.k8s.pod.worker.emptydirs指定的 emptyDir 卷。配置值中的每个目录都映射到一个 emptyDir 卷。 - 使用配置键
mr3.k8s.pod.worker.hostpaths指定的 hostPath 卷。配置值中的每个目录(应该在主机节点上就绪)都映射到一个 hostPath 卷。 - 使用配置键
mr3.k8s.worker.local.dir.persistentvolumes以及mr3.k8s.local.dir.persistentvolume.storageclass和mr3.k8s.local.dir.persistentvolume.storage指定的 persistentVolumeClaim 卷(挂载 PersistentVolumes)。配置值中的每个目录都映射到一个 persistentVolumeClaim 卷,该卷根据mr3.k8s.local.dir.persistentvolume.storageclass指定的存储类(例如 EBS 的gp2)和mr3.k8s.local.dir.persistentvolume.storage指定的大小(例如2Gi)动态创建。
对于 Amazon EKS,第一个选项仅适用于以低并发级别运行小查询,因为根分区很小(默认 20GB)。或者,用户可以使用 eksctl 创建 EKS 集群时的 --node-volume-size 标志增加根分区的大小。如果使用实例存储(物理附加到主机节点),第二个选项可提供最佳性能(成本略高)。第三个选项仅在有限情况下有效:1) EKS 集群应在单个可用区中运行,2) Docker 容器应以 root 用户身份运行。
要使用第二个选项,用户应创建一个 EKS 集群,其 mr3-worker 节点组使用的 EC2 实例类型配备了实例存储。此外,mr3-worker 节点组规范中的 preBootstrapCommands 字段应包含用于格式化和挂载实例存储的命令。
在我们的示例中,我们使用第二个选项。
配置 EKS 集群
打开 cluster.yaml。为 EKS 集群设置区域。
vi cluster.yaml
metadata:
region: ap-northeast-2
我们创建具有两个节点组的 EKS 集群:mr3-master 和 mr3-worker。
mr3-master节点组用于 HiveServer2、DAGAppMaster 和 Metastore Pod。在我们的示例中,我们为 master 节点使用单个按需实例,类型为m5.xlarge。mr3-worker节点组用于 ContainerWorker Pod。在我们的示例中,我们为工作节点使用最多三个 spot 实例,类型为m5d.xlarge。需要注意的是,工作节点有实例存储。如果eksctl需要mr3-worker节点组的至少两个实例类型,请将其升级到最新版本。
vi cluster.yaml
nodeGroups:
- name: mr3-master
instanceType: m5.xlarge
desiredCapacity: 1
- name: mr3-worker
desiredCapacity: 0
minSize: 0
maxSize: 3
instancesDistribution:
instanceTypes: ["m5d.xlarge"]
onDemandBaseCapacity: 0
onDemandPercentageAboveBaseCapacity: 0
在节点组 mr3-master 和 mr3-worker 的 iam.attachPolicyARNs 字段中,使用前一步骤中创建的 IAM 策略的 ARN。(如果不使用 mr3-master 的 ARN,用户将无法检查 Kubernetes Autoscaler 的状态。)
vi cluster.yaml
nodeGroups:
- name: mr3-master
iam:
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- arn:aws:iam::123456789012:policy/EKSAutoScalingWorkerPolicy
- arn:aws:iam::123456789012:policy/MR3AccessS3
- name: mr3-worker
iam:
attachPolicyARNs:
- arn:aws:iam::aws:policy/AmazonEKSWorkerNodePolicy
- arn:aws:iam::aws:policy/AmazonEKS_CNI_Policy
- arn:aws:iam::123456789012:policy/EKSAutoScalingWorkerPolicy
- arn:aws:iam::123456789012:policy/MR3AccessS3
在节点组 mr3-worker 的 preBootstrapCommands 字段中,列出用于初始化实例存储的命令。在我们的示例中,我们在目录 /ephemeral1 上挂载单个本地磁盘。需要注意的是,/ephemeral1 的所有者设置为 ec2-user,其 UID 1000 与 Docker 镜像中用户 hive 的 UID 匹配。
vi cluster.yaml
nodeGroups:
- name: mr3-worker
preBootstrapCommands:
- "IDX=1; for DEV in /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_*-ns-1; do mkfs.xfs ${DEV}; mkdir -p /ephemeral${IDX}; echo ${DEV} /ephemeral${IDX} xfs defaults,noatime 1 2 >> /etc/fstab; IDX=$((${IDX} + 1)); done"
- "mount -a"
- "IDX=1; for DEV in /dev/disk/by-id/nvme-Amazon_EC2_NVMe_Instance_Storage_*-ns-1; do chown ec2-user:ec2-user /ephemeral${IDX}; IDX=$((${IDX} + 1)); done"
默认情况下,命令 eksctl 使用 metadata.region 字段指定的区域中的所有可用区(AZ)。因此,ContainerWorker Pod 通常分布在多个 AZ 上,可能无法与 HiveServer2 Pod 共置。然而,使用多个 AZ 可能会产生意想不到的后果,因为Amazon 对不同 AZ 之间的数据传输收费($0.01/GB 到 $0.02/GB),而且 ContainerWorkers 交换的中间数据可能跨越 AZ 边界。具体来说,ContainerWorkers 非常频繁且大量地交换中间数据,数据传输成本可能高得惊人,有时甚至超过 EC2 实例的总成本。
因此,用户可能希望将 EKS 集群限制在单个 AZ 以避免高昂的数据传输成本。用户可以通过如下更新 cluster.yaml 来使用单个 AZ。(如果 eksctl 不接受此更新,请将其升级到最新版本。)
vi cluster.yaml
availabilityZones: ["ap-northeast-2a", "ap-northeast-2b", "ap-northeast-2c"]
nodeGroups:
- name: mr3-master
availabilityZones: ["ap-northeast-2a"]
- name: mr3-worker
availabilityZones: ["ap-northeast-2a"]
AZONE=ap-northeast-2a
环境变量 AZONE 稍后会用到。
创建 EKS 集群
通过执行命令 eksctl 创建 EKS 集群。下图显示了 EKS 集群启动后的示例:
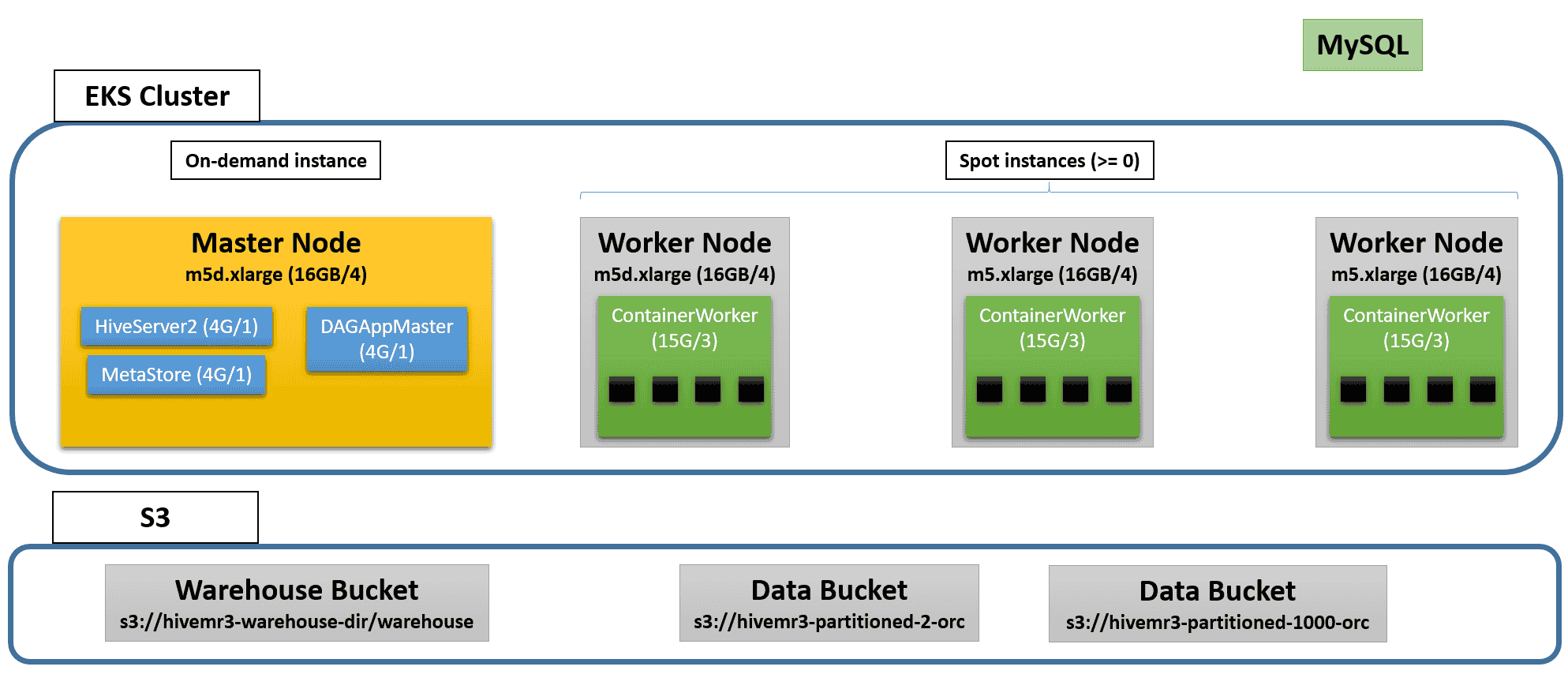
创建 EKS 集群可能需要 15 分钟或更长时间。获取 CloudFormation 堆栈 eksctl-hive-mr3-cluster 的名称。
eksctl create cluster -f cluster.yaml
2025-05-01 22:50:19 [ℹ] eksctl version 0.207.0
2025-05-01 22:50:19 [ℹ] using region ap-northeast-2...
2025-05-01 23:04:03 [✔] EKS cluster "hive-mr3" in "ap-northeast-2" region is ready
获取 CloudFormation eksctl-hive-mr3-cluster 的 VPC ID。
VPCID=$(aws ec2 describe-vpcs --filter Name=tag:aws:cloudformation:stack-name,Values=eksctl-hive-mr3-cluster --query "Vpcs[0].VpcId" --output text)
echo "$VPCID"
vpc-0394968e116d238e2
获取 CloudFormation eksctl-hive-mr3-cluster 的公共子网 ID。
SUBNETID=$(aws ec2 describe-subnets --filter Name=vpc-id,Values=$VPCID Name=availability-zone,Values=$AZONE Name=tag:aws:cloudformation:stack-name,Values=eksctl-hive-mr3-cluster Name=tag:Name,Values="*Public*" --query "Subnets[0].SubnetId" --output text)
echo "$SUBNETID"
subnet-0895b6cd4f381ad31
用户可以看到已创建多个安全组。获取与模式 eksctl-hive-mr3-cluster-ClusterSharedNodeSecurityGroup-* 匹配的 EKS 集群的安全组 ID。
SGROUPALL=$(aws ec2 describe-security-groups --filters Name=vpc-id,Values=$VPCID Name=group-name,Values="eksctl-hive-mr3-cluster-ClusterSharedNodeSecurityGroup-*" --query "SecurityGroups[0].GroupId" --output text)
echo "$SGROUPALL"
sg-068049732c8cc61cf
用户可以看到已创建两个自动扩缩容组。
aws autoscaling describe-auto-scaling-groups --region ap-northeast-2 --query "AutoScalingGroups[*].[AutoScalingGroupName]" --output text
eksctl-hive-mr3-nodegroup-mr3-master-NodeGroup-dGaIVkZ6q5BK
eksctl-hive-mr3-nodegroup-mr3-worker-NodeGroup-fNgGpmo0WUVd

在我们的示例中,mr3-master 节点组从一个 master 节点开始,而 mr3-worker 节点组从没有节点开始,但最多可以附加三个节点。
用户可以验证 EKS 集群中只有 master 节点可用。
kubectl get nodes
NAME STATUS ROLES AGE VERSION
ip-192-168-27-229.ap-northeast-2.compute.internal Ready <none> 25m v1.32.1-eks-5d632ec
用户可以获取 master 节点的公共 IP 地址。
kubectl describe node ip-192-168-27-229.ap-northeast-2.compute.internal | grep "IP: "
InternalIP: 192.168.27.229
ExternalIP: 3.38.153.151
配置 Kubernetes Autoscaler
如果启用了自动扩缩容,打开 cluster-autoscaler-autodiscover.yaml 并设置 AWS_REGION 和 AWS_DEFAULT_REGION。根据需要更改自动扩缩容的配置。默认情况下,Kubernetes Autoscaler 会删除空闲 1 分钟的节点(如 --scale-down-unneeded-time 所指定)。
vi cluster-autoscaler-autodiscover.yaml
spec:
template:
spec:
containers:
env:
- name: AWS_REGION
value: ap-northeast-2
- name: AWS_DEFAULT_REGION
value: ap-northeast-2
command:
- --scale-down-delay-after-add=5m
- --scale-down-unneeded-time=1m
启动 Kubernetes Autoscaler。
kubectl apply -f cluster-autoscaler-autodiscover.yaml
serviceaccount/cluster-autoscaler created
clusterrole.rbac.authorization.k8s.io/cluster-autoscaler created
role.rbac.authorization.k8s.io/cluster-autoscaler created
clusterrolebinding.rbac.authorization.k8s.io/cluster-autoscaler created
rolebinding.rbac.authorization.k8s.io/cluster-autoscaler created
deployment.apps/cluster-autoscaler created
用户可以检查 Kubernetes Autoscaler 是否已正确启动。
kubectl logs -f deployment/cluster-autoscaler -n kube-system
...
I0501 14:43:00.497780 1 static_autoscaler.go:598] Starting scale down
I0501 14:43:00.497802 1 legacy.go:298] No candidates for scale down
(可选)创建和挂载 EFS 文件系统
下面我们描述如何通过 PersistentVolume 使用外部存储供应器(而不是 Amazon EFS CSI 驱动)创建和挂载 EFS 文件系统。
1) 创建 EFS 文件系统
用户可以在 AWS 控制台上创建 EFS 文件系统。创建 EFS 时,请选择 EKS 集群的 VPC。确保为每个可用区创建挂载目标。获取 EFS 的文件系统 ID(例如 fs-0d9698da20942d8bf)。如果用户可以为挂载目标选择安全组,请使用 EKS 集群的安全组(在 SGROUPALL 中)。
或者,用户可以使用 AWS CLI 创建 EFS 文件系统。在要运行 HivePlus 的可用区中创建 EFS。获取 EFS 的文件系统 ID。
EFSID=$(aws efs create-file-system --performance-mode generalPurpose --throughput-mode bursting --availability-zone-name $AZONE --query 'FileSystemId' --output text)
echo "$EFSID"
fs-0d9698da20942d8bf
使用 CloudFormation eksctl-hive-mr3-cluster 的子网 ID 和 EKS 集群的安全组 ID 创建挂载目标。获取挂载目标 ID,这在删除 EKS 集群时是必需的。
MOUNTID=$(aws efs create-mount-target --file-system-id $EFSID --subnet-id $SUBNETID --security-groups $SGROUPALL --query 'MountTargetId' --output text)
echo "$MOUNTID"
fsmt-098e2c5a065bc3ca0
2) 必要时配置安全组
如果用户无法为挂载目标选择安全组,则应手动配置安全组。识别两个安全组:1) 构成 EKS 集群的 EC2 实例的安全组;2) 与 EFS 挂载目标关联的安全组。
对于第一个安全组(用于 EC2 实例),添加一条规则,允许从任何主机使用安全外壳(SSH)入站访问,以便 EFS 可以访问 EKS 集群,如下所示:
对于第二个安全组,添加一条规则,允许从第一个安全组使用 NFS 入站访问,以便 EKS 集群可以访问 EFS,如下所示:
为了检查 EKS 集群是否可以将 EFS 挂载到其 EC2 实例上的本地目录,请获取 EFS 的文件系统 ID(例如 fs-0d9698da20942d8bf)和区域 ID(例如 ap-northeast-2)。然后登录到 EC2 实例并执行以下命令。
mkdir -p /home/ec2-user/efs
sudo mount -t nfs -o nfsvers=4.1,rsize=1048576,wsize=1048576,hard,timeo=600,retrans=2,noresvport fs-0d9698da20942d8bf.efs.ap-northeast-2.amazonaws.com:/ /home/ec2-user/efs
如果安全组配置正确,EFS 将挂载到目录 /home/ec2-user/efs。
3) 创建 StorageClass
我们使用 AWS EFS 的外部存储供应器(可从 https://github.com/kubernetes-sigs/sig-storage-lib-external-provisioner 获取)来为 EFS 创建 StorageClass。外部存储供应器通过在 EFS 上创建 PersistentVolumes 来帮助请求 EFS 的 StorageClass 的 PersistentVolumeClaims。
要为 EFS 创建 StorageClass,目录 efs 包含四个 YAML 文件,用于启动 EFS 的存储供应器并创建 PersistentVolumeClaim workdir-pvc。在 efs/manifest.yaml 中设置 EFS 的文件系统 ID、区域 ID 和 NFS 服务器地址。
vi efs/manifest.yaml
data:
file.system.id: fs-0d9698da20942d8bf
aws.region: ap-northeast-2
provisioner.name: example.com/aws-efs
dns.name: ""
spec:
template:
spec:
volumes:
- name: pv-volume
nfs:
server: fs-0d9698da20942d8bf.efs.ap-northeast-2.amazonaws.com
path: /
将环境变量 MR3_NAMESPACE 设置为命名空间,然后执行脚本 mount-efs.sh 来创建 PersistentVolume。
vi mount-efs.sh
MR3_NAMESPACE=hivemr3
./mount-efs.sh
namespace/hivemr3 created
serviceaccount/efs-provisioner created
clusterrole.rbac.authorization.k8s.io/efs-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/run-efs-provisioner created
role.rbac.authorization.k8s.io/leader-locking-efs-provisioner created
rolebinding.rbac.authorization.k8s.io/leader-locking-efs-provisioner created
configmap/efs-provisioner created
deployment.apps/efs-provisioner created
storageclass.storage.k8s.io/aws-efs created
persistentvolumeclaim/workdir-pvc created
用户可以找到新的 StorageClass aws-efs、运行存储供应器的新 Pod(例如 efs-provisioner-88bc4d8b6-588qg)和新的 PersistentVolumeClaim workdir-pvc。PersistentVolumeClaim workdir-pvc 的容量没有限制,因此用户可以忽略其标称容量 1Mi。HivePlus 的所有 Pod 将共享 PersistentVolumeClaim workdir-pvc。
kubectl get sc
NAME PROVISIONER RECLAIMPOLICY VOLUMEBINDINGMODE ALLOWVOLUMEEXPANSION AGE
aws-efs example.com/aws-efs Delete Immediate false 23s
gp2 kubernetes.io/aws-ebs Delete WaitForFirstConsumer false 62m
kubectl get pods -n hivemr3
NAME READY STATUS RESTARTS AGE
efs-provisioner-88bc4d8b6-588qg 1/1 Running 0 49s
kubectl get pvc -n hivemr3
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS VOLUMEATTRIBUTESCLASS AGE
workdir-pvc Bound pvc-e9161aad-6358-48fd-a194-c0c129447481 1Mi RWX aws-efs <unset> 75s
用户可以验证 EFS 上已为 PersistentVolumeClaim workdir-pvc 创建了新目录。
kubectl exec -n hivemr3 -it efs-provisioner-88bc4d8b6-588qg -- apk add bash
kubectl exec -n hivemr3 -it efs-provisioner-88bc4d8b6-588qg -- /bin/bash -c "ls /persistentvolumes"
workdir-pvc-pvc-e9161aad-6358-48fd-a194-c0c129447481
配置 HivePlus
EKS 集群准备就绪后,用户可以继续阅读在 Kubernetes 上的快速入门指南。
配置 HivePlus 时,conf/core-site.xml 和 conf/mr3-site.xml 中的大多数配置键都可以使用其默认值。下面介绍几个应该由用户自定义的配置键。
- 使用
InstanceProfileCredentialsProvider作为凭证提供程序。这样,用户就不需要 AWS 访问密钥和秘密密钥。
vi conf/core-site.xml
<property>
<name>fs.s3a.aws.credentials.provider</name>
<value>com.amazonaws.auth.InstanceProfileCredentialsProvider</value>
</property>
- 在 MR3 中启用自动扩缩容。
vi conf/mr3-site.xml
<property>
<name>mr3.enable.auto.scaling</name>
<value>true</value>
</property>
- 将
mr3.k8s.pod.worker.hostpaths设置为/ephemeral1,因为工作节点的实例类型m5d.xlarge配备了在目录/ephemeral1上挂载的单个本地磁盘。
vi conf/mr3-site.xml
<property>
<name>mr3.k8s.pod.worker.hostpaths</name>
<value>/ephemeral1</value>
</property>
如果用户使用具有多个本地磁盘的不同实例类型,则应扩展节点组 mr3-worker 的 preBootstrapCommands 字段以挂载所有本地磁盘,并且配置键 mr3.k8s.pod.worker.hostpaths 应包含其他目录。
- 由于 Kubernetes Autoscaler 配置为在空闲 1 分钟后删除保持空闲的节点以实现快速缩容,请将
mr3.auto.scale.in.grace.period.secs设置为 90 秒(60 秒空闲时间加上额外的 30 秒以考虑延迟)。如果用户想增加cluster-autoscaler-autodiscover.yaml中--scale-down-unneeded-time的值,则应相应调整mr3.auto.scale.in.grace.period.secs的值。
vi conf/mr3-site.xml
<property>
<name>mr3.auto.scale.in.grace.period.secs</name>
<value>90</value>
</property>
- 为防止 MR3 过早取消工作节点的配置,请将
mr3.auto.scale.out.grace.period.secs设置为足够大的值。例如,如果创建和初始化新工作节点大约需要 3 分钟,则可以将mr3.auto.scale.out.grace.period.secs设置为 300(相当于 5 分钟)。有关更多详细信息,请参阅自动扩缩容。
vi conf/mr3-site.xml
<property>
<name>mr3.auto.scale.out.grace.period.secs</name>
<value>300</value>
</property>
-
通过更新
conf/hive-site.xml来更改分配给每个 mapper、reducer 和 ContainerWorker 的资源。特别是,配置键hive.mr3.all-in-one.containergroup.memory.mb和hive.mr3.all-in-one.containergroup.vcores应该调整,以便 ContainerWorker 可以适应工作节点。例如,对于实例类型m5d.xlarge的工作节点,我们可以使用以下值。hive.mr3.map.task.memory.mb=3000hive.mr3.map.task.vcores=0hive.mr3.reduce.task.memory.mb=3000hive.mr3.reduce.task.vcores=0hive.mr3.all-in-one.containergroup.memory.mb=14000hive.mr3.all-in-one.containergroup.vcores=3
配置 LoadBalancer
执行 HiveServer2 会创建一个新的 LoadBalancer。获取与 LoadBalancer 关联的安全组。如有必要,编辑入站规则以限制源 IP 地址(例如,通过将源从 0.0.0.0/0 更改为 (IP address)/32)。

LoadBalancer 会在空闲超时期间(默认 60 秒)断开没有活动的 Beeline 连接。用户可能希望增加空闲超时时间,例如增加到 1200 秒。否则,Beeline 在短暂不活动后就会失去与 HiveServer2 的连接。
运行 Beeline
要运行 Beeline,请获取 Service hiveserver2 的 LoadBalancer Ingress。
kubectl describe service -n hivemr3 hiveserver2
Name: hiveserver2
Namespace: hivemr3
Labels: <none>
Annotations: <none>
Selector: hivemr3_app=hiveserver2
Type: LoadBalancer
IP: 10.100.87.74
External IPs: 1.1.1.1
LoadBalancer Ingress: a5002d0aff1bb4773aa04dc2bcc205bf-39738783.ap-northeast-2.elb.amazonaws.com
...
获取 LoadBalancer Ingress 的 IP 地址。
nslookup a5002d0aff1bb4773aa04dc2bcc205bf-39738783.ap-northeast-2.elb.amazonaws.com
...
Non-authoritative answer:
Name: a5002d0aff1bb4773aa04dc2bcc205bf-39738783.ap-northeast-2.elb.amazonaws.com
Address: 3.36.135.212
Name: a5002d0aff1bb4773aa04dc2bcc205bf-39738783.ap-northeast-2.elb.amazonaws.com
Address: 13.124.55.22
在这个示例中,用户可以使用 3.36.135.212 或 13.124.55.22 作为运行 Beeline 时 HiveServer2 的 IP 地址。这是因为 Beeline 首先连接到 LoadBalancer,而不是直接连接到 HiveServer2。
运行几个查询后,新的工作节点被附加,ContainerWorker Pod 被创建。在我们的示例中,EKS 集群最终有三个工作节点。最后一个 ContainerWorker Pod 保持 Pending 状态,因为工作节点数量已达到其最大值(我们示例中为 3),并且无法附加更多工作节点。
kubectl get pods -n hivemr3
NAME READY STATUS RESTARTS AGE
efs-provisioner-88bc4d8b6-588qg 1/1 Running 0 7m39s
hivemr3-hiveserver2-769f575878-m57h8 1/1 Running 0 4m11s
hivemr3-metastore-0 1/1 Running 0 4m46s
mr3master-3983-0-84c7b6c7c5-2nw74 1/1 Running 0 3m55s
mr3worker-9649-1 1/1 Running 0 113s
mr3worker-9649-2 1/1 Running 0 113s
mr3worker-9649-3 1/1 Running 0 113s
mr3worker-9649-4 0/1 Pending 0 113s
以下是当配置键 mr3.auto.scale.out.num.initial.containers 在 conf/mr3-site.xml 中设置为 1 时,扩容操作的进度:
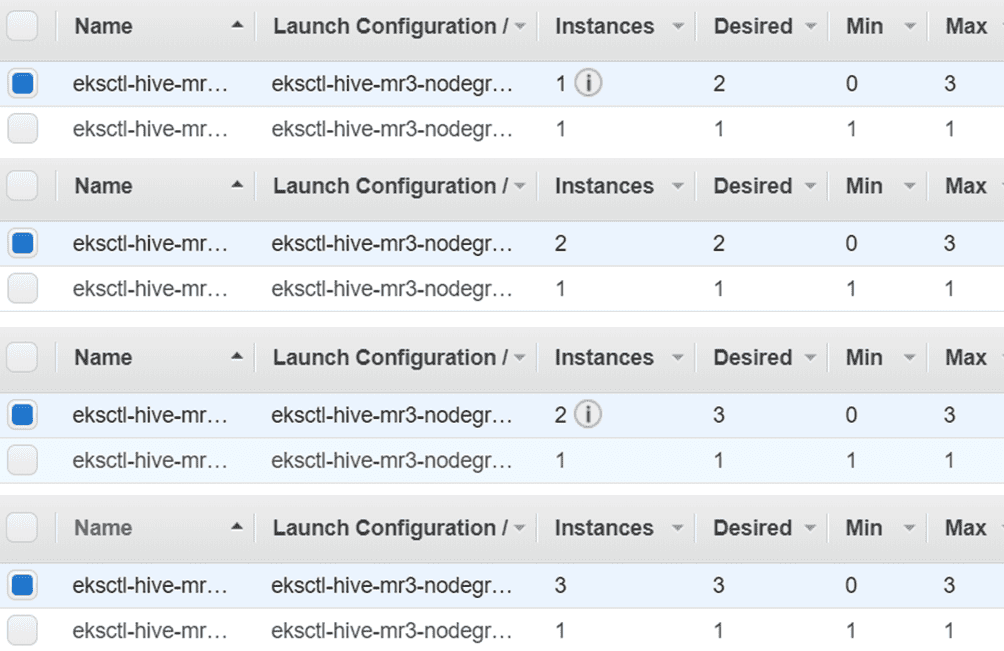
以下是缩容操作的进度:
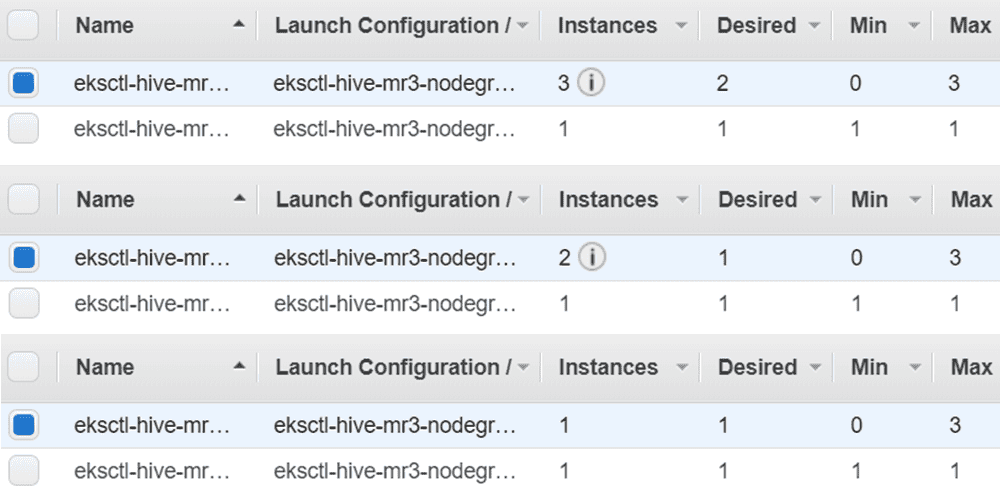
需要注意的是,EKS 集群不会删除所有工作节点,因为 mr3-site.xml 中的配置键 mr3.auto.scale.in.min.hosts 设置为 1,这意味着如果工作节点数量为 1,则不会执行缩容操作。
用户可以从 DAGAppMaster Pod 的日志中检查自动扩缩容的进度。
kubectl logs -n hivemr3 mr3master-3983-0-84c7b6c7c5-2nw74 -f | grep -e Scale -e Scaling -e average
删除 EKS 集群
由于手动配置了其他组件,删除 EKS 集群需要几个额外的步骤。要删除 EKS 集群(使用 eksctl 创建),请按以下顺序继续。
- 停止 HiveServer2、DAGAppMaster 和 Metastore。
kubectl -n hivemr3 delete deployment hivemr3-hiveserver2
deployment.apps "hivemr3-hiveserver2" deleted
kubectl delete deployment -n hivemr3 mr3master-3983-0
deployment.apps "mr3master-3983-0" deleted
kubectl -n hivemr3 delete statefulset hivemr3-metastore
statefulset.apps "hivemr3-metastore" deleted
- 删除 HivePlus 的所有资源。
kubectl -n hivemr3 delete configmap hivemr3-conf-configmap client-am-config mr3conf-configmap-master mr3conf-configmap-worker
kubectl -n hivemr3 delete svc --all
kubectl -n hivemr3 delete secret env-secret hivemr3-keytab-secret hivemr3-worker-secret
kubectl -n hivemr3 delete serviceaccount hive-service-account master-service-account worker-service-account
kubectl -n hivemr3 delete role hive-role master-role worker-role
kubectl -n hivemr3 delete rolebinding hive-role-binding master-role-binding worker-role-binding
kubectl delete clusterrole node-reader
kubectl delete clusterrolebinding hive-clusterrole-binding
kubectl delete pv --all
- 删除 EFS 的资源。
kubectl delete -f efs/service-account.yaml
kubectl delete -f efs/workdir-pvc.yaml
kubectl delete -f efs/manifest.yaml
kubectl delete -f efs/rbac.yaml
- 删除命名空间
hivemr3。
kubectl delete namespace hivemr3
- 如果创建了 EFS,请删除 EFS 的挂载目标。
aws efs delete-mount-target --mount-target-id $MOUNTID
- 如果创建了 EFS,请删除 EFS。
aws efs delete-file-system --file-system-id $EFSID
- 停止 Kubernetes Autoscaler
kubectl delete -f cluster-autoscaler-autodiscover.yaml
- 使用
eksctl删除 EKS。
kubectl delete pdb -n kube-system coredns metrics-server
eksctl delete cluster -f cluster.yaml
...
2025-05-02 00:39:13 [✔] all cluster resources were deleted
如果最后一个命令失败,用户应手动删除 EKS 集群。请在 AWS 控制台上按以下顺序继续。
- 手动删除安全组。
- 删除为 EKS 集群创建的 NAT 网关,删除 VPC,然后删除弹性 IP 地址。
- 删除 LoadBalancer。
- 删除 IAM 角色。
- 删除 CloudFormation。