故障排查
通用问题
java.lang.OutOfMemoryError
对于OutOfMemoryError问题没有通用解决方案。以下是减少 MR3 内存压力的一些建议。
-
增加分配给每个 mapper、reducer 或 ContainerWorker 的内存量。请参阅 资源配置。
-
为了避免使用空闲内存存储 shuffle 输出(当启用流水线 shuffling 时),在
tez-site.xml中将tez.runtime.use.free.memory.writer.output设置为 false。请参阅 内存设置 了解更多详情。 -
为了避免使用空闲内存存储 shuffle 输入,在
tez-site.xml中将tez.runtime.use.free.memory.fetched.input设置为 false。如果tez.runtime.use.free.memory.fetched.input应设置为 true,请将tez.runtime.free.memory.factor.for.fetched.input设置为较小的值(例如 2.0 而不是 6.0)。请参阅 内存设置 了解更多详情。 -
如果从
PipelinedSorter.allocateSpace()执行失败并出现OutOfMemoryError,则tez-site.xml中配置键tez.runtime.io.sort.mb的值对于可用内存量来说太大。请参阅 内存设置 了解更多详情。 -
如果在有序 shuffle 期间发生
OutOfMemoryError,请尝试使用tez-site.xml中tez.runtime.shuffle.merge.percent的较小值。 -
**对于执行批处理查询,**在
mr3-site.xml中将mr3.container.task.failure.num.sleeps设置为非零值。请参阅 OutOfMemoryError。
Map Vertex 在Initializing状态卡住
有时 Map Vertex 在 DAGAppMaster 中生成 InputSplits 时可能会在Initializing状态卡住很长时间。这种情况通常发生在 DAGAppMaster 扫描大量输入文件时,特别是当输入数据存储在 S3 上时。
----------------------------------------------------------------------------------------------
VERTEX MODE STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
----------------------------------------------------------------------------------------------
Map 1 llap Initializing -1 0 0 -1 0 0
Reducer 2 llap New 4 0 0 4 0 0
Reducer 3 llap New 1 0 0 1 0 0
在这种情况下,用户可以尝试以下方法。
- 如果有很多小输入文件,请合并它们。
- 在
hive-site.xml中将hive.exec.orc.split.strategy设置为BI。 - 如果输入数据存储在 S3 上,
- 增加
mapreduce.input.fileinputformat.list-status.num-threads和hive.exec.input.listing.max.threads的值(可以在 Beeline 连接内或通过重启 HiveServer2 进行)。这里我们假设 DAGAppMaster 被分配了足够的 CPU 资源。 - 调整
core-site.xml中fs.s3a.block.size的值。
- 增加
查询因过多获取失败而失败
查询可能会在获取失败后失败:
Caused by: java.io.IOException: Map_1: Shuffle failed with too many fetch failures and insufficient progress! failureCounts=1, pendingInputs=1, fetcherHealthy=false, reducerProgressedEnough=true, reducerStalled=true
在以下示例中,Map 1最初成功,但后来因为Reducer 2经历多次获取失败而重新运行其任务。
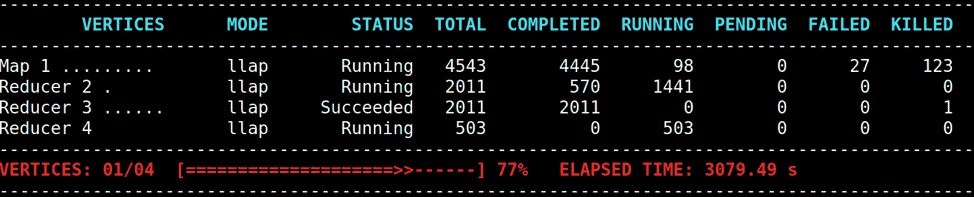
在这种情况下,用户可以尝试以下方法来减少获取失败的机会或从获取失败中恢复。
- 启用流水线 shuffling 并使用空闲内存存储 shuffle 输入/输出,以最大程度地减少磁盘访问。
- 减少
tez-site.xml中配置键tez.runtime.shuffle.total.parallel.copies的值(例如从 360 减少到 180),以减少每个 ContainerWorker 中的并发 fetchers 总数。 - 减少
tez-site.xml中配置键tez.runtime.shuffle.parallel.copies的值(例如从 10 减少到 5),以减少每个 LogicalInput(它们都并行运行)的 fetchers 数量。这可以减少 shuffle handlers 端的负载,因为来自 reducers 的同时请求更少。 - 如果连接尝试经常失败,请增加
tez-site.xml中配置键tez.runtime.shuffle.connect.timeout的值(例如设置为 17500)。
请参阅 Shuffle 配置 了解更多详情。
Map Vertex 生成过多任务,下游 Vertex 卡住或因OutOfMemoryError失败
如果 Map Vertex 的 mapper 数量成为性能问题(例如由于下游 reducers 生成的过多 shuffle 请求),用户可以调整配置键tez.grouping.min-size和tez.grouping.max-size来减少 mapper 的数量。
或者,用户可以直接将配置键tez.grouping.split-count设置为所需的 mapper 数量。当 mappers 生成 Bloom filters 时,这一点特别重要,因为其大小与 mapper 的总数无关。在这种情况下,下游 reducers 的执行时间几乎与 mapper 的数量成正比,因此将tez.grouping.split-count设置为较小的值会立即产生效果。
MR3 DAGAppMaster 即使在空闲时也显示中等到高 CPU 使用率
当大型集群中运行许多 ContainerWorkers 时,通常会出现这种情况。每个 ContainerWorker 按配置键mr3.container.busy.wait.interval.ms指定的固定间隔向 DAGAppMaster 发送消息以获取要执行的下一个命令。默认情况下,ContainerWorkers 每 25 毫秒联系一次 DAGAppMaster,每秒发送约 40 条消息。当 DAGAppMaster 空闲(不处理 DAG)时,其 CPU 使用率主要用于处理来自 ContainerWorkers 的这些消息。在具有许多 ContainerWorkers 的大型集群中,用户可以增加mr3.container.busy.wait.interval.ms的值(例如增加到 100)以减少 CPU 使用率。
启动 HivePlus 后执行的第一个查询不使用任务位置提示
MR3 使用 ContainerWorkers 当前运行位置的任务位置提示。例如,任务位置提示 'foo' 仅在 ContainerWorker 当前在节点 'foo' 上运行时才有效。因此,对于在没有任何 ContainerWorkers 运行时执行的任何查询,计数器NUM_HOST_LOCAL_TASK_ATTEMPTS为 0(或接近 0)。
调用 UDF 或使用 JdbcStorageHandler 的查询因ClassNotFoundException失败
如果出于安全原因将配置键mr3.am.permit.custom.user.class设置为 false,则在 DAGAppMaster 内部运行的 InputInitializer、VertexManager 或 OutputCommitter 可能无法使用自定义 Java 类。因此,调用 UDF 或使用 JdbcStorageHandler 的查询可能尝试加载自定义 Java 类并生成ClassNotFoundException。为了防止这种情况下的ClassNotFoundException,在mr3-site.xml中将mr3.am.permit.custom.user.class设置为 true。
Metastore 即使将hive.stats.autogather和hive.stats.column.autogather都设置为 true 也不收集所有列统计信息
用户应手动执行analyze table命令。
加载表失败并出现FileAlreadyExistsException
FileAlreadyExistsException的一个示例是:
Caused by: org.apache.hadoop.fs.FileAlreadyExistsException: Failed to rename s3a://hivemr3/warehouse/tpcds_bin_partitioned_orc_1000.db/.hive-staging_hive_2023-05-17_07-37-59_392_7290354321306036074-2/-ext-10002/000000_0/delta_0000001_0000001_0000/bucket_00000 to s3a://hivemr3/warehouse/tpcds_bin_partitioned_orc_1000.db/web_site/delta_0000001_0000001_0000/bucket_00000; destination file exists
这通常发生在启用 推测执行 时。用户可以通过在hive-site.xml中将配置键hive.mr3.am.task.concurrent.run.threshold.percent设置为 100.0 来禁用推测执行。
访问 S3 的查询失败并出现SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
这可能发生在 DAGAppMaster 执行 InputInitializer 时,在这种情况下,Beeline 和 DAGAppMaster 会生成此类错误:
### 来自 Beeline
ERROR : FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.tez.TezTask. Terminating unsuccessfully: Vertex failed, vertex_22169_0000_1_02, Some(RootInput web_sales failed on Vertex Map 1: com.datamonad.mr3.api.common.AMInputInitializerException: web_sales)
Map 1 1 task 2922266 milliseconds: Failed
### 来自 DAGAppMaster
Caused by: java.lang.RuntimeException: ORC split generation failed with exception: java.io.InterruptedIOException: Failed to open s3a://hivemr3-partitioned-2-orc/web_sales/ws_sold_date_sk=2451932/000001_0 at 14083 on s3a://hivemr3-partitioned-2-orc/web_sales/ws_sold_date_sk=2451932/000001_0: com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
这也可能在 ContainerWorkers 中发生,在这种情况下 ContainerWorkers 会生成此类错误:
.....
com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
at org.apache.hadoop.fs.s3a.S3AUtils.translateInterruptedException(S3AUtils.java:340)
~[hadoop-aws-3.1.2.jar:?]
...
Caused by: com.amazonaws.SdkClientException: Unable to execute HTTP request: Timeout waiting for connection from pool
根据 S3 桶的设置和数据集的属性,用户可能需要调整core-site.xml中以下配置键的值。
- 增加
fs.s3a.connection.maximum的值(例如增加到 2000 或更高) - 增加
fs.s3a.threads.max的值 - 增加
fs.s3a.threads.core的值 - 将
fs.s3a.blocking.executor.enabled设置为 false
更多详情请参阅 访问 S3。
非确定性查询(即每次执行结果可能不同的查询)即使启用容错也可能失败
默认情况下,MR3 假设 DAG 由确定性 Vertex 组成,在给定相同输入时输出始终相同。然而,非确定性查询会产生具有不确定性 Vertex 的 DAG,其输出可能因执行而异。
为了处理这种情况,用户必须通过将配置键hive.mr3.dag.include.indeterminate.vertex设置为 true 来通知 MR3 存在不确定性 Vertex。需要注意的是,当发生获取失败时,不支持这些 DAG 的容错。
Iceberg
加载 Iceberg 表失败
错误消息的一个示例是:
org.apache.iceberg.exceptions.NotFoundException: Can not read or parse commitTask manifest file: hdfs://kbhadoop01:9000/hivemr3/warehouse/blacklight.db/monthly_question_i/temp/hive_20250508170807_7d7e1f3e-8bf3-4b7a-80fa-205d2cb48a7b-job_80331_0000/task-584.forCommit
这可能发生在启用 推测执行 时。用户可以通过在hive-site.xml中将配置键hive.mr3.am.task.concurrent.run.threshold.percent设置为 100.0 来禁用推测执行。
在 Hadoop 上
访问 HDFS 的查询失败并出现org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block
访问 HDFS 的查询可能失败并出现BlockMissingException:
java.lang.RuntimeException: org.apache.hadoop.hive.ql.metadata.HiveException: java.io.IOException: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1848301428-10.1.90.9-1589952347981:blk_1078550925_4810302 file=/tmp/tpcds-generate/10000/catalog_returns/data-m-08342...
Caused by: org.apache.hadoop.hdfs.BlockMissingException: Could not obtain block: BP-1848301428-10.1.90.9-1589952347981:blk_1078550925_4810302 file=/tmp/tpcds-generate/10000/catalog_returns/data-m-08342
at org.apache.hadoop.hdfs.DFSInputStream.refetchLocations(DFSInputStream.java:875)
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:858)
at org.apache.hadoop.hdfs.DFSInputStream.chooseDataNode(DFSInputStream.java:837)
at org.apache.hadoop.hdfs.DFSInputStream.blockSeekTo(DFSInputStream.java:566)
at org.apache.hadoop.hdfs.DFSInputStream.readWithStrategy(DFSInputStream.java:756)
at org.apache.hadoop.hdfs.DFSInputStream.read(DFSInputStream.java:825)
at java.io.DataInputStream.read(DataInputStream.java:149)
...
即使 HDFS 块实际可用,也可能发生此错误。它通常发生在数据仓库包含过多小文件时。对于 Hive 3 on MR3,用户应在创建新表之前将配置键hive.optimize.sort.dynamic.partition设置为 true。将hive.merge.tezfiles设置为 true 也有助于避免创建过多小文件。
此错误也可能是由于某些配置键的值过小造成的。例如,用户可以尝试调整以下配置键。
hive.exec.max.dynamic.partitions.pernode(例如从默认值 1000 增加到 100000)hive.exec.max.dynamic.partitions(例如从默认值 100 增加到 100000)
在 Kubernetes 上
Metastore 找不到数据库连接器 jar 文件并出现ClassNotFoundException
如果 Metastore 找不到数据库连接器 jar 文件,它会打印类似以下的错误消息:
2020-07-18T04:03:14,856 ERROR [main] tools.HiveSchemaHelper: Unable to find driver class
java.lang.ClassNotFoundException: com.mysql.jdbc.Driver
Metastore 的类路径包括 Metastore Pod 内的目录/opt/mr3-run/lib和/opt/mr3-run/host-lib,用户可以将自定义数据库连接器 jar 文件放在这两个目录之一中,如下所示。
如果有 PersistentVolume 可用,用户可以将数据库连接器 jar 文件复制到 PersistentVolume 的子目录lib,并在yaml/metastore.yaml中使用 PersistentVolumeClaimwork-dir-volume。然后 jar 文件挂载在 Metastore Pod 内的目录/opt/mr3-run/lib中。
vi yaml/metastore.yaml
spec:
template:
spec:
containers:
volumeMounts:
- name: work-dir-volume
mountPath: /opt/mr3-run/lib
subPath: lib
使用 Helm 时,用户应在hive/values.yaml中将metastore.mountLib设置为 true。
vi hive/values.yaml
metastore:
mountLib: true
如果没有 PersistentVolume 可用(例如当使用 HDFS/S3 时),用户可以使用 hostPath volume 将其挂载到目录/opt/mr3-run/host-lib。
vi yaml/metastore.yaml
spec:
template:
spec:
containers:
volumeMounts:
- name: host-lib-volume
mountPath: /opt/mr3-run/host-lib
使用 Helm 时,hive/values.yaml应将metastore.hostLib设置为 true,并将metastore.hostLibDir设置为包含所有 worker 节点上 jar 文件的公共本地目录。
vi hive/values.yaml
metastore:
hostLib: true
hostLibDir: "/home/ec2-user/lib"
DAGAppMaster Pod 无法启动,因为mr3-conf.properties不存在
MR3 从 ConfigMapmr3conf-configmap-master生成属性文件mr3-conf.properties并将其挂载到 DAGAppMaster Pod 内部。如果 DAGAppMaster Pod 失败并显示以下错误消息,则意味着 ConfigMapmr3conf-configmap-master已损坏或mr3-conf.properties尚未生成。
2020-05-15T10:35:10,255 ERROR [main] DAGAppMaster: Error in starting DAGAppMaster
java.lang.IllegalArgumentException: requirement failed: Properties file mr3-conf.properties does not exist
在这种情况下,请尝试手动删除 ConfigMapmr3conf-configmap-master后再试,以便 HivePlus 可以在没有同名 ConfigMap 的情况下启动。
ContainerWorker Pod 永远不会被启动
尝试调整 DAGAppMaster 和 ContainerWorker Pod 的资源。在conf/mr3-site.xml中,用户可以调整 DAGAppMaster Pod 的资源。
<property>
<name>mr3.am.resource.memory.mb</name>
<value>16384</value>
</property>
<property>
<name>mr3.am.resource.cpu.cores</name>
<value>2</value>
</property>
在conf/hive-site.xml中,用户可以调整 ContainerWorker Pod 的资源。
<property>
<name>hive.mr3.all-in-one.containergroup.memory.mb</name>
<value>16384</value>
</property>
<property>
<name>hive.mr3.all-in-one.containergroup.vcores</name>
<value>2</value>
</property>
访问 S3 的查询没有进展,因为 Map vertex 在Initializing状态卡住
如果 DAGAppMaster 无法解析主机名,查询的执行可能会卡在以下状态:

在这种情况下,请检查conf/mr3-site.xml中的配置键mr3.k8s.host.aliases是否设置正确。例如,如果用户在env.sh中将环境变量HIVE_DATABASE_HOST设置为主机名(而不是 MySQL 服务器的地址),则其地址应在mr3.k8s.host.aliases中指定。
在内部,类AmazonS3Client(在 MR3 的InputInitializer内部运行)会抛出异常java.net.UnknownHostException,但该异常被吞没,永远不会传播到 DAGAppMaster。因此,没有错误报告,查询会卡住。
查询失败并出现DiskErrorException: No space available in any of the local directories
查询可能失败并出现DiskErrorException:
ERROR : Terminating unsuccessfully: Vertex failed, vertex_2134_0000_1_01, Some(Task unsuccessful: Map 1, task_2134_0000_1_01_000000, java.lang.RuntimeException: org.apache.hadoop.util.DiskChecker$DiskErrorException: No space available in any of the local directories.
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:370)
...
Caused by: org.apache.hadoop.util.DiskChecker$DiskErrorException: No space available in any of the local directories.
在这种情况下,请检查conf/mr3-site.xml中的配置键mr3.k8s.pod.worker.hostpaths是否设置正确,例如:
<property>
<name>mr3.k8s.pod.worker.hostpaths</name>
<value>/data1/k8s,/data2/k8s,/data3/k8s,/data4/k8s,/data5/k8s,/data6/k8s</value>
</property>
此外,请检查mr3.k8s.pod.worker.hostpaths中列出的目录是否对 UID 为 1000 的用户可写。
Kubernetes 上的 Kerberos
Metastore 失败并出现javax.security.auth.login.LoginException: ICMP Port Unreachable
如果 KDC 设置不正确,Metastore 可能会失败并出现LoginException:
Exception in thread "main" org.apache.hadoop.security.KerberosAuthException: failure to login: for principal: hive/admin@PL from keytab /opt/mr3-run/key/hive-admin.keytab javax.security.auth.login.LoginException: ICMP Port Unreachable
当 Metastore 无法通过端口 88 和 749 到达 KDC 服务器时,会发生此错误。特别是,确保 KDC 服务器可通过 UDP 端口 88 和 749 以及 TCP 端口 88 和 749 到达。
Beeline 失败并出现org.ietf.jgss.GSSException
即使有有效的 Kerberos 票据可用,Beeline 也可能失败并出现GSSException:
javax.security.sasl.SaslException: GSS initiate failed
...
Caused by: org.ietf.jgss.GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)
at sun.security.jgss.krb5.Krb5InitCredential.getInstance(Krb5InitCredential.java:147)
~[?:1.8.0_112]
at sun.security.jgss.krb5.Krb5MechFactory.getCredentialElement(Krb5MechFactory.java:122)
~[?:1.8.0_112]
at sun.security.jgss.krb5.Krb5MechFactory.getMechanismContext(Krb5MechFactory.java:187)
~[?:1.8.0_112]
at sun.security.jgss.GSSManagerImpl.getMechanismContext(GSSManagerImpl.java:224)
~[?:1.8.0_112]
at sun.security.jgss.GSSContextImpl.initSecContext(GSSContextImpl.java:212)
~[?:1.8.0_112]
at sun.security.jgss.GSSContextImpl.initSecContext(GSSContextImpl.java:179)
~[?:1.8.0_112]
at com.sun.security.sasl.gsskerb.GssKrb5Client.evaluateChallenge(GssKrb5Client.java:192)
~[?:1.8.0_112]
在这种情况下,添加 Java 选项-Djavax.security.auth.useSubjectCredsOnly=false可能有效。
KrbApErrException: Message stream modified或KrbException: Message stream modified
由于 Kerberos 中的一个 bug,HivePlus 可能即使有有效的 keytab 文件也无法认证。在这种情况下,它通常会打印错误消息KrbApErrException: Message stream modified。
org.apache.hive.service.ServiceException: Unable to login to kerberos with given principal/keytab...
Caused by: org.apache.hadoop.security.KerberosAuthException: failure to login: for principal: hive/gold7@PL from keytab /opt/mr3-run/key/hive.service.keytab javax.security.auth.login.LoginException: Message stream modified (41)...
Caused by: sun.security.krb5.internal.KrbApErrException: Message stream modified (41)
at sun.security.krb5.KrbKdcRep.check(KrbKdcRep.java:101)
~[?:1.8.0_242]
at sun.security.krb5.KrbAsRep.decrypt(KrbAsRep.java:159)
~[?:1.8.0_242]
at sun.security.krb5.KrbAsRep.decryptUsingKeyTab(KrbAsRep.java:121)
~[?:1.8.0_242]
at sun.security.krb5.KrbAsReqBuilder.resolve(KrbAsReqBuilder.java:308)
~[?:1.8.0_242]
at sun.security.krb5.KrbAsReqBuilder.action(KrbAsReqBuilder.java:447)
~[?:1.8.0_242]
at com.sun.security.auth.module.Krb5LoginModule.attemptAuthentication(Krb5LoginModule.java:780)
~[?:1.8.0_242]
该 bug 的根本原因未知,用户应找到特定于 Docker 镜像的修复方法。用户可以通过移除krb5.conf中renew_lifetime的设置来尝试解决方法。
vi conf/krb5.conf
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
forwardable = true
# renew_lifetime = 7d
rdns = false
default_realm = RED
default_ccache_name = /tmp/krb5cc_%{uid}
DAGAppMaster 打印错误消息User ... cannot perform AM view operations
env.sh中DOCKER_USER的用户与HIVE_SERVER2_KERBEROS_PRINCIPAL中的服务名称不匹配会导致 HiveServer2 无法建立到 DAGAppMaster 的连接。在这种情况下,DAGAppMaster 会持续打印类似以下的错误消息:
2019-07-04T09:42:17,074 WARN [IPC Server handler 0 on 8080] ipc.Server: IPC Server handler 0 on 8080, call Call#32 Retry#0 com.datamonad.mr3.master.DAGClientHandlerProtocolBlocking.getSessionStatus from 10.43.0.0:37962
java.security.AccessControlException: User gitlab-runner/indigo20@RED (auth:TOKEN) cannot perform AM view operations
at com.datamonad.mr3.master.DAGClientHandlerProtocolServer.checkAccess(DAGClientHandlerProtocolServer.scala:239)
~[mr3-tez-0.1-assembly.jar:0.1]
at com.datamonad.mr3.master.DAGClientHandlerProtocolServer.checkViewAccess(DAGClientHandlerProtocolServer.scala:233)
~[mr3-tez-0.1-assembly.jar:0.1]
...
如果在 DAGAppMaster 中禁用了权限检查,ContainerWorkers 会打印类似以下的错误消息:
2020-08-16T16:34:01,019 ERROR [Tez Shuffle Handler Worker #1] shufflehandler.ShuffleHandler: Shuffle error :
java.io.IOException: Owner 'root' for path /data1/k8s/dag_1/container_K@1/vertex_3/attempt_70888998_0000_1_03_000000_0_10003/file.out did not match expected owner 'hive'
at org.apache.hadoop.io.SecureIOUtils.checkStat(SecureIOUtils.java:281)
~[hadoop-common-3.1.2.jar:?]
更多详情请参阅 Kubernetes 上的 Kerberos 认证 在 Kubernetes 上。
使用加密(启用 Kerberos 的)HDFS 时,执行没有输入文件的查询失败并出现AccessControlException
如果使用了加密 HDFS,创建新表或向现有表插入值可能会失败,而仅读取数据的查询可以正常工作。
... org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]...
如果hive-site.xml中未设置配置键hive.mr3.dag.additional.credentials.source,则会发生此错误。更多详情请参阅 访问 HDFS。
类似的错误可能在 DAGAppMaster 生成 splits 时发生。(DAGAppMaster 的日志报告与每个 DAG 关联的凭据。)
2023-08-31 15:24:19,402 [main] INFO ContainerWorker [] - Credentials for Y@container_1694103365516_0016_01_000004: SecretKeys = 0, Tokens = 2: List(HDFS_DELEGATION_TOKEN, mr3.job)...
2023-08-31 16:19:08,183 [DAG1-Input-4-3] WARN org.apache.hadoop.ipc.Client [] - Exception encountered while connecting to the server : org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
2023-08-31 16:19:08,195 [DAG1-Map 1] ERROR Vertex [] - RootInput order_detail failed on Vertex Map 1
com.datamonad.mr3.api.common.AMInputInitializerException: order_detail
at ...
Caused by: java.io.IOException: org.apache.hadoop.security.AccessControlException: Client cannot authenticate via:[TOKEN, KERBEROS]
在这种情况下,请检查core-site.xml中是否设置了配置键dfs.encryption.key.provider.uri或hadoop.security.key.provider.path。更多详情请参阅 访问 HDFS。
Ranger
HiveServer2 在下载 Ranger 策略时抛出NullPointerException,Beeline 无法执行查询
HiveServer2 无法下载 Ranger 策略并生成NullPointerException:
2020-10-08T12:23:08,872 ERROR [Thread-6] util.PolicyRefresher: PolicyRefresher(serviceName=ORANGE_hive): failed to refresh policies. Will continue to use last known version of policies (-1)
com.sun.jersey.api.client.ClientHandlerException: java.lang.RuntimeException: java.lang.NullPointerException
...
Caused by: java.lang.NullPointerException
Beeline 由于缺乏权限而无法执行查询:
0: jdbc:hive2://orange1:9852/> use tpcds_bin_partitioned_orc_1003;
Error: Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user [gitlab-runner] does not have [USE] privilege on [tpcds_bin_partitioned_orc_1000] (state=42000,code=40000)
在"Config Properties"面板中将policy.download.auth.users设置为包含 HiveServer2 的用户后,这些错误可能会消失。

"Config Properties"面板中的"Test Connection"失败
检查jdbc.url字段是否设置正确。示例如下:
- 当既不使用 Kerberos 也不使用 SSL 时:
jdbc:hive2://indigo20:9852/ - 当使用 Kerberos 时:
jdbc:hive2://indigo20:9852/;principal=hive/indigo20@RED; - 当同时使用 Kerberos 和 SSL 时:
jdbc:hive2://indigo20:9852/;principal=hive/indigo20@RED;ssl=true;sslTrustStore=/opt/mr3-run/ranger/key/hivemr3-ssl-certificate.jks;
Apache Ranger Admin Service 无法启动
为了找出失败的原因,请检查 Ranger Pod 内 Ranger 容器(不是 Solr 容器)中的文件catalina.out。在以下示例中,Admin Service 无法启动是因为提供了错误的 Kerberos keytab 文件。
kubectl exec -it -n hivemr3 hivemr3-ranger-0 -c ranger /bin/bash;
root@hivemr3-ranger-0:/opt/mr3-run/ranger# cat work-local-dir/log/ranger-admin/catalina.out
…
SEVERE: Tomcat Server failed to start:
java.io.IOException: Login failure for rangeradmin/orange1@PL from keytab /opt/mr3-run/ranger/key/rangeradmin.keytab
java.io.IOException: Login failure for rangeradmin/orange1@PL from keytab /opt/mr3-run/ranger/key/rangeradmin.keytab
...
Caused: java.security.GeneralSecurityException: Checksum failed...