单表调优
HivePlus 的默认配置针对涉及多个表之间 join 操作的批处理和交互式查询进行了优化。对于分析单个表的更简单查询,hive-site.xml 中的配置键 hive.optimize.reducededuplication 可以产生差异。
hive.optimize.reducededuplication
考虑对单个表 trade_record 的以下查询。
SELECT shop_id, partner, COUNT(DISTINCT unique_id) FROM trade_record GROUP BY shop_id, partner;
如果键 unique_id 的不同值数量相对较小,默认配置效果很好。在我们的示例中,我们假设该数量接近记录总数。
> SELECT COUNT(*) FROM trade_record;9769696688> SELECT COUNT(DISTINCT unique_id) FROM trade_record;5361347747
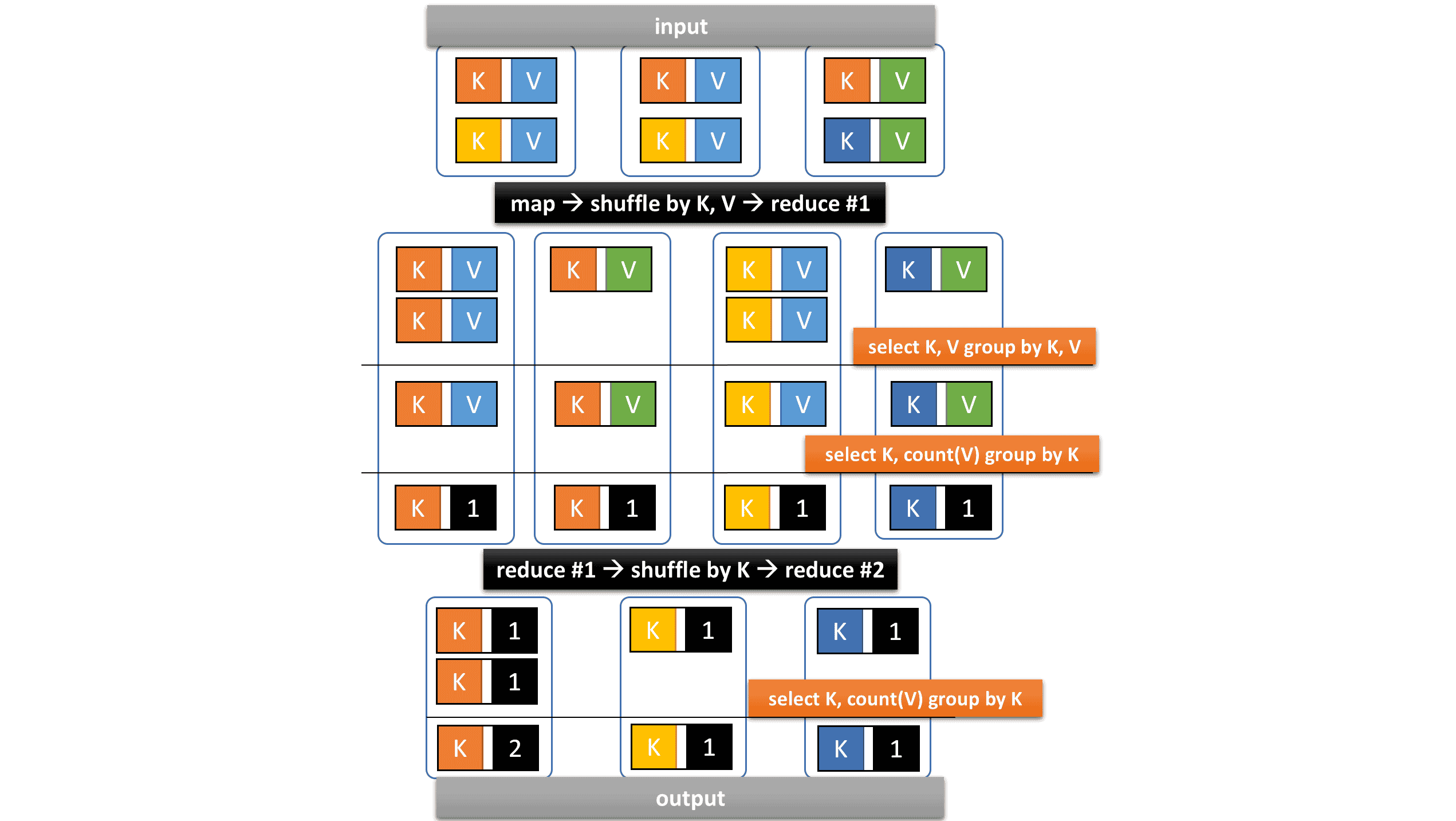
默认情况下,配置键 hive.optimize.reducededuplication 设置为 true,HivePlus 生成以下查询计划,其中键 K 对应 (shop_id, partner),值 V 对应 unique_id。
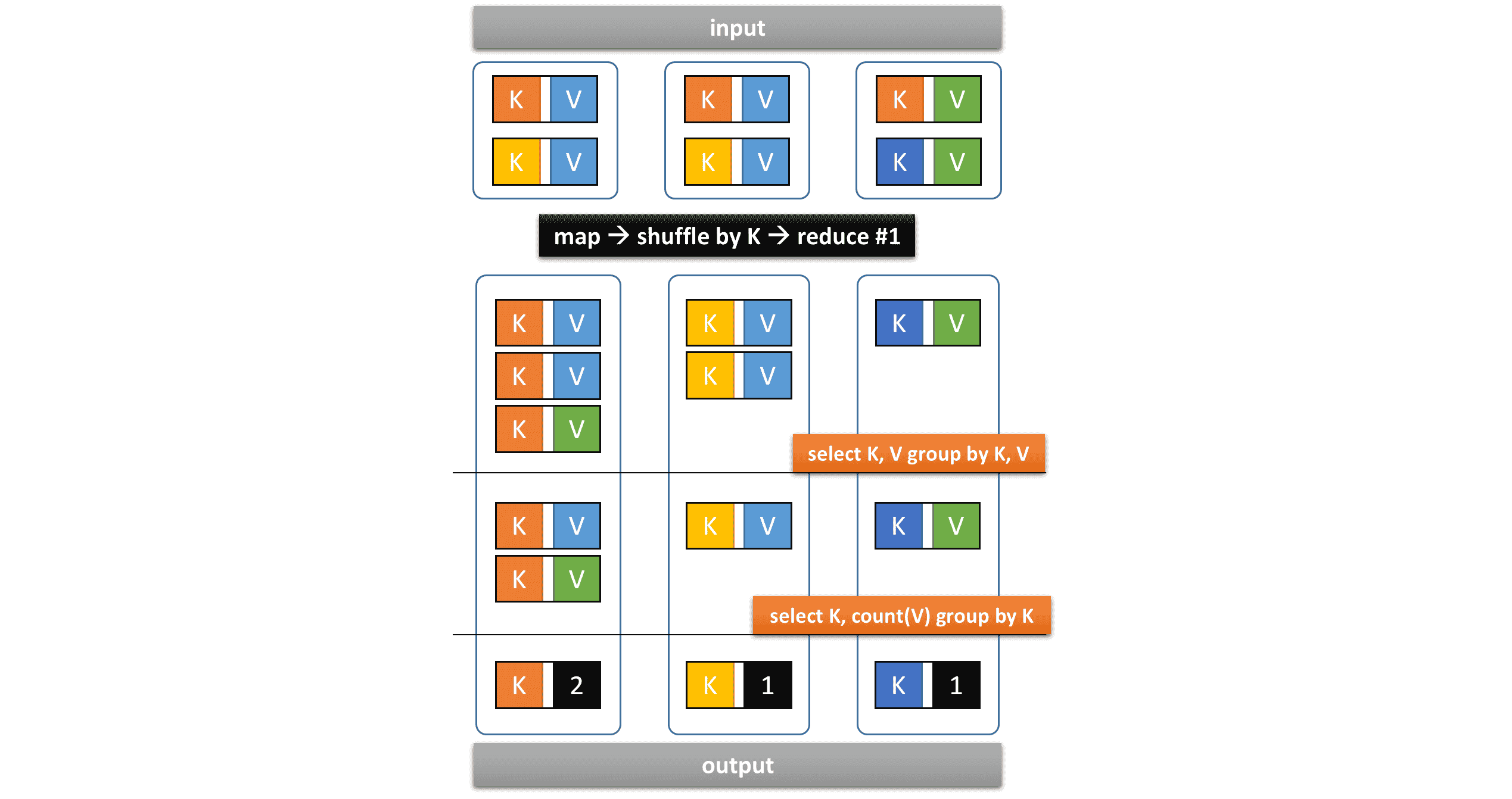
查询计划已经优化,因为两个 GROUP BY 运算符在单个 Vertex 中执行,但这可能成为性能瓶颈。我们可以将 hive.optimize.reducededuplication 设置为 false 以将 Vertex 拆分为两个。引入了一个新的 shuffle 阶段,但总执行时间可能会减少,因为更多 Task 可以并发执行。