Shuffle 配置
HivePlus 的性能受其 shuffle 配置的高度影响。涉及 shuffle 的关键组件有:1) ShuffleServer 和 2) shuffle handlers。
ShuffleServer 管理向远程 ContainerWorker 发送 fetch 请求的 fetcher,而 shuffle handlers 通过管理来自远程 ContainerWorker 的 fetch 请求来提供 shuffle 服务。
配置 ShuffleServer
HivePlus 在一个通用的 ShuffleServer 下集中管理所有 fetcher(请参阅 管理 Fetcher)。
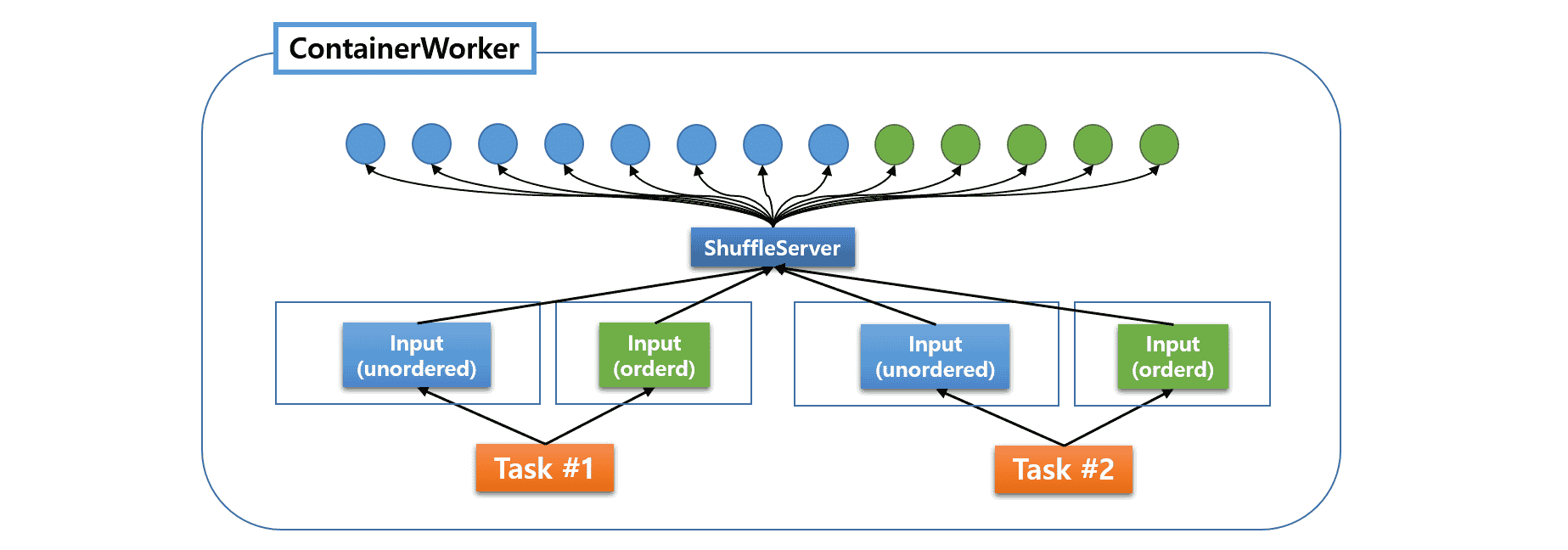
在选择 ContainerWorker 的资源和并发级别后,用户应在 tez-site.xml 中调整两个配置键。
tez.runtime.shuffle.parallel.copies指定单个 LogicalInput 可以请求的最大并发 fetcher 数量。tez.runtime.shuffle.total.parallel.copies指定可以在 ContainerWorker 内运行的最大并发 fetcher 数量。
我们建议从以下设置开始:
- 将
tez.runtime.shuffle.parallel.copies设置为 10 - 将
tez.runtime.shuffle.total.parallel.copies设置为 10 * 分配给每个 ContainerWorker 的核心总数
使用 MR3 shuffle handlers
默认情况下,HivePlus 使用 MR3 shuffle handlers 而不是外部 shuffle 服务。mr3-site.xml 和 tez-site.xml 中的以下配置键使 MR3 的运行时系统能够将中间数据路由到 MR3 shuffle handlers。
mr3-site.xml中的mr3.use.daemon.shufflehandler指定每个 ContainerWorker 中的 shuffle handlers 数量。如果其值大于零,ContainerWorker 会创建自己的 shuffle handlers 线程。如果设置为零,则不创建 shuffle handlers,MR3 使用外部 shuffle 服务。tez-site.xml中的tez.am.shuffle.auxiliary-service.id应设置为tez_shuffle以使用 MR3 shuffle handlers。在 Hadoop 上,它可以设置为mapreduce_shuffle以使用 Hadoop shuffle 服务,在这种情况下,mr3.use.daemon.shufflehandler被忽略。
运行太多 shuffle handlers 或每个 shuffle handler 创建太多线程可能会对资源有限的 ContainerWorker 上的性能产生负面影响。因此,用户可能需要调整 tez-site.xml 中配置键 tez.shuffle.max.threads 的值,以限制 shuffle handlers 的线程总数。例如,在具有 40 个核心的节点上,将 tez.shuffle.max.threads 设置为默认值 0 会为每个 shuffle handler 创建 2 * 40 = 80 个线程。如果 mr3.use.daemon.shufflehandler 设置为 20,则 ContainerWorker 为 shuffle handlers 创建总计 80 * 20 = 1600 个线程,这可能过多。
对于运行 HivePlus,用户可以在 hive-site.xml 中设置 hive.mr3.use.daemon.shufflehandler,它映射到 mr3.use.daemon.shufflehandler。
我们建议从以下设置开始:
- 将
tez.shuffle.max.threads设置为 20 - 将
hive.mr3.use.daemon.shufflehandler设置为分配给每个 ContainerWorker 的核心总数 / 2
流水线 shuffle
MR3 中的 shuffle 以流水线模式或非流水线模式进行。
- 使用流水线 shuffle 时,每当 TaskAttempt 的输出缓冲区被填满时,会向下游 TaskAttempt 发送一条消息(类型为
DataMovementEvent)。因此,下游 TaskAttempt 可以通过几个交错的 shuffle 请求来获取上游 TaskAttempt 的输出数据。 - 使用非流水线 shuffle 时,只有在整个输出数据可用并在单个输出文件中合并后,才会向下游 TaskAttempt 发送一条消息。因此,下游 TaskAttempt 发出单个 shuffle 请求来获取上游 TaskAttempt 的输出数据。
用户可以通过在 tez-site.xml 中将配置键 tez.runtime.pipelined-shuffle.enabled 设置为 true 来启用流水线 shuffle。
要使用流水线 shuffle,建议禁用投机执行(通过在 hive-site.xml 中将 hive.mr3.am.task.concurrent.run.threshold.percent 设置为 100.0),以避免为同一 Task 启动多个并发 TaskAttempt。这是因为使用流水线 shuffle 时,来自不同 TaskAttempt 的部分结果可能不会在下游 TaskAttempt 中混合。具体来说,下游 TaskAttempt 在收到来自不同上游 TaskAttempt 的部分结果时会自行终止。
基于 10TB TPC-DS 基准测试的实验结果表明,流水线 shuffle 通常可以提高 HivePlus 的性能。流水线 shuffle 下的容错也能正常工作。配置键 tez.runtime.pipelined-shuffle.enabled 在 MR3 发布版本中设置为 true。
我们建议将流水线 shuffle 作为默认模式。然而,对于可能偶尔触发容错的长时间运行的批处理查询,我们建议使用非流水线 shuffle,因为它更稳定。
压缩中间数据
压缩中间数据通常会获得更好的 shuffle 性能。用户可以通过在 tez-site.xml 中设置以下两个配置键来压缩中间数据。
tez.runtime.compress应设置为 true。tez.runtime.compress.codec应设置为压缩中间数据的编解码器。
默认情况下,tez.runtime.compress.codec 在 tez-site.xml 中设置为 org.apache.hadoop.io.compress.SnappyCodec。在 Hadoop 上,应在每个节点上手动安装 Snappy 库。在 Kubernetes 和独立模式下,Snappy 库已包含在 MR3 发布版本中。
用户也可以在使用 Zstandard 库并设置 tez.runtime.compress.codec 为 org.apache.hadoop.io.compress.ZStandardCodec 后使用 Zstandard 压缩。但是,如果查询生成大型中间文件(例如超过 25MB),可能会失败。
本地磁盘
ContainerWorker 在本地磁盘上写入中间数据,因此使用快速存储作为本地磁盘(如 NVMe SSD)总是会提高 shuffle 性能。使用多个本地磁盘也比使用单个本地磁盘更好,因为 HivePlus 在创建用于存储中间数据的文件时会轮换本地磁盘。
背压
tez-site.xml 中的配置键 tez.shuffle.max.block.requests.thread.multiple 指定一个乘数,用于计算触发背压的活动 shuffle 请求总数的阈值:
tez.shuffle.max.block.requests.thread.multiple* shuffle handlers 总数 =tez.shuffle.max.block.requests.thread.multiple*mr3.use.daemon.shufflehandler*tez.shuffle.max.threads
tez.shuffle.max.block.requests.thread.multiple 的默认值是 2。将其设置为更大的值(例如 3)以允许更多活动 shuffle 请求。
投机 fetch
在典型环境中,MR3 发布版本中投机 fetch 的默认设置通常可以很好地防止fetch 延迟:
tez.runtime.shuffle.speculative.fetch.wait.millis= 12500tez.runtime.shuffle.stuck.fetcher.threshold.millis= 2500tez.runtime.shuffle.stuck.fetcher.release.millis= 7500tez.runtime.shuffle.max.speculative.fetch.attempts= 2
默认设置特别适合交互式查询,因为投机 fetcher 相对较快地创建:在检测到停滞 fetcher 后约 5 秒(7500 - 2500 = 5000 毫秒)。对于执行长时间运行的批处理查询或 shuffle 重查询,更容易发生 fetch 延迟,因此不太积极的设置可能更合适。例如,用户可以使用以下设置:
tez.runtime.shuffle.speculative.fetch.wait.millis= 30000tez.runtime.shuffle.stuck.fetcher.threshold.millis= 2500tez.runtime.shuffle.stuck.fetcher.release.millis= 17500tez.runtime.shuffle.max.speculative.fetch.attempts= 2
有序记录的内存到内存合并 vs 基于磁盘的合并
默认情况下,HivePlus 执行内存到内存合并来合并从上游 vertex shuffle 的有序记录。
vi tez-site.xml
<property>
<name>tez.runtime.shuffle.memory-to-memory.enable</name>
<value>true</value>
</property>
如果每个 reducer 中要合并的有序记录数量很大,基于磁盘的合并可能更有效。要切换到基于磁盘的合并,将 tez.runtime.shuffle.memory-to-memory.enable 设置为 false。
配置内核参数
减少 fetch 延迟 机会的常见解决方案是调整一些内核参数以防止数据包丢失。例如,用户可以调整集群中每个节点上的以下内核参数:
- 增加
net.core.somaxconn的值(例如从默认值 128 增加到 16384) - 可选增加
net.ipv4.tcp_max_syn_backlog的值(例如增加到 65536) - 可选减少
net.ipv4.tcp_fin_timeout的值(例如减少到 30)
不幸的是,配置内核参数只是一个部分解决方案,不能完全消除 fetch 延迟。这是因为如果应用程序在处理连接请求时很慢,TCP listen 队列最终会满,fetch 延迟也会随之而来。换句话说,如果不优化应用程序本身,仅调整内核参数,我们永远无法完全消除 fetch 延迟。
配置网络接口
网络接口的节点配置也会影响 fetch 延迟的机会。例如,如果在工作节点上的网络接口上启用了散列-聚集功能,则可能因数据包丢失而频繁发生 fetch 延迟。
ethtool -k p1p1...scatter-gather: on tx-scatter-gather: on tx-scatter-gather-fraglist: off [fixed]
在这种情况下,用户可以在网络接口上禁用相关功能。
ethtool -K p1p1 sg off
防止 fetch 延迟
在 MR3 中,通常通过启用投机 fetch 来防止 fetch 延迟。如果尽管有投机 fetch 仍然存在 fetch 延迟,用户可以尝试 MR3 的两个功能:在 ContainerWorker 中运行多个 shuffle handlers 和投机执行。
要检查 fetch 延迟,请通过将配置键 hive.query.results.cache.enabled 设置为 false 来禁用查询结果缓存,并多次运行 shuffle 重查询。如果执行时间不稳定且波动很大,则 fetch 延迟可能是原因。
要启用投机执行,请在 hive-site.xml 中将配置键 hive.mr3.am.task.concurrent.run.threshold.percent 设置为开始监视 TaskAttempt 投机执行之前已完成的 Task 的百分比。用户还应将配置键 hive.mr3.am.task.max.failed.attempts 设置为同一 Task 的最大 TaskAttempt 数量。在以下示例中,ContainerWorker 等待 99% 的 Task 完成后再开始监视 TaskAttempt,并为同一 Task 最多创建 3 个 TaskAttempt。
vi conf/hive-site.xml
<property>
<name>hive.mr3.am.task.concurrent.run.threshold.percent</name>
<value>99.0</value>
</property>
<property>
<name>hive.mr3.am.task.max.failed.attempts</name>
<value>3</value>
</property>
配置连接超时
tez-site.xml 中的配置键 tez.runtime.shuffle.connect.timeout 指定尝试连接到外部 shuffle 服务或内置 shuffle handlers 以报告 fetch 失败的最大时间(以毫秒为单位)。具体来说,TaskAttempt 向 DAGAppMaster 报告 fetch 失败的逻辑如下。如果 TaskAttempt 未能连接到为源 TaskAttempt 服务的外部 shuffle 服务或内置 shuffle handlers,它会在等待直到 tez.runtime.shuffle.connect.timeout 指定的持续时间内每次重试 5 秒(如 org.apache.tez.http.BaseHttpConnection 中 UNIT_CONNECT_TIMEOUT 所指定)。
以下是几个示例:
- 如果
tez.runtime.shuffle.connect.timeout设置为 2500,它永远不会重试并立即报告 fetch 失败。 - 如果
tez.runtime.shuffle.connect.timeout设置为 7500,它会在等待 5 秒后仅重试一次。 - 如果
tez.runtime.shuffle.connect.timeout设置为 12500,它最多重试两次,每次等待 5 秒。 - 如果
tez.runtime.shuffle.connect.timeout设置为默认值 27500,它最多重试五次,每次等待 5 秒。
如果在与 shuffle 服务或内置 shuffle handler 成功连接后发生错误,TaskAttempt 会立即报告 fetch 失败。以下是此类错误的几种情况:
- 运行源 TaskAttempt 的 Hadoop shuffle 服务的主机突然崩溃。
- 保存源 TaskAttempt 输出的 ContainerWorker 进程突然终止。
- 源 TaskAttempt 的输出被损坏或删除。
如果由于磁盘访问或网络拥塞的争用而连接失败过于频繁,使用较大的 tez.runtime.shuffle.connect.timeout 值可能是一个好决定,因为它会导致更多重试,从而减少 fetch 失败的机会。(如果连接失败是由于硬件问题,则无论 tez.runtime.shuffle.connect.timeout 的值如何,最终都会报告 fetch 失败。)
另一方面,使用过大的值可能会大大延迟 fetch 失败的报告,比 Task/Vertex 重新运行花费的时间更长,从而显著增加查询的执行时间。因此,用户应选择一个适当的值,以合理快速地触发 Task/Vertex 重新运行。