管理 Fetcher
单独的 ShuffleServer
在 Apache Hive(以及 MR3 的初始版本)中,fetcher 由单独的 LogicalInput 管理。一个 Task 可以有多个 LogicalInput,每个 LogicalInput 管理自己的 fetcher 组和 ShuffleServer 实例:
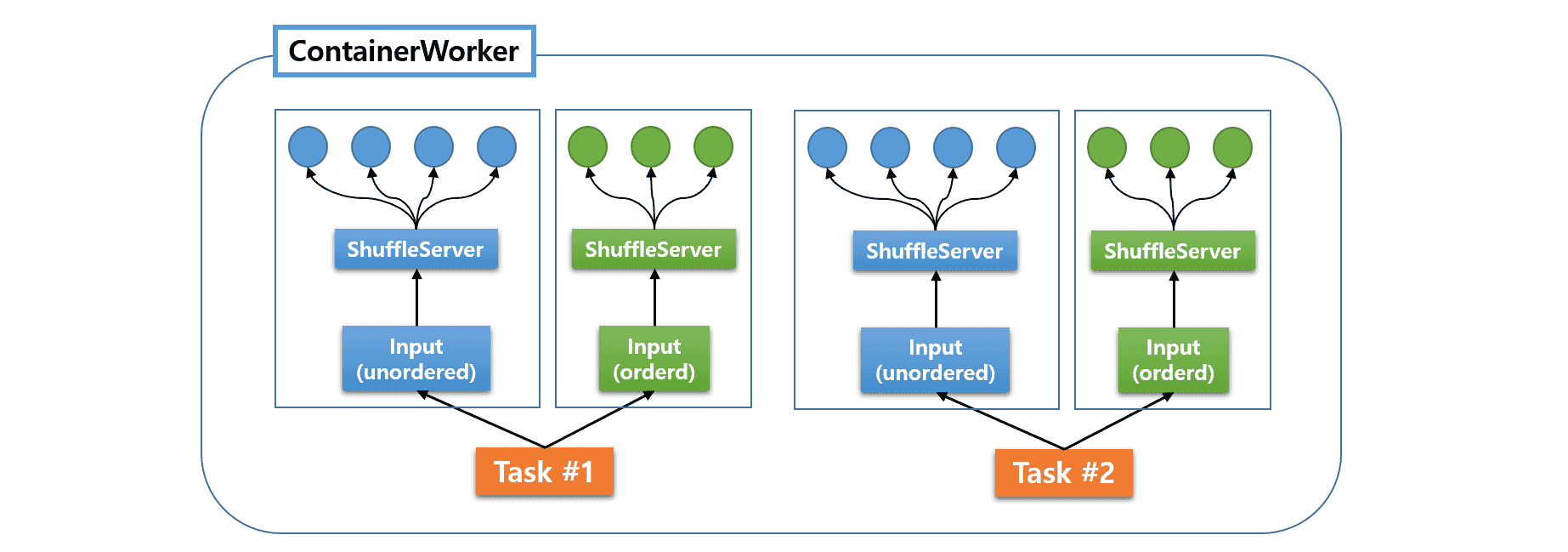
在上图中,蓝色圆圈表示无序数据的 fetcher,绿色圆圈表示有序数据的 fetcher。由于我们只能限制每个 LogicalInput 的 fetcher 总数,ContainerWorker 可能会意外创建太多 fetcher。因此,fetcher 的性能并不总是稳定的,Fetch 延迟的机会也会增加。
公共 ShuffleServer
相比之下,MR3 的运行时系统使用了一种高级架构,将所有 fetcher 的管理集中在一个公共 ShuffleServer 下。
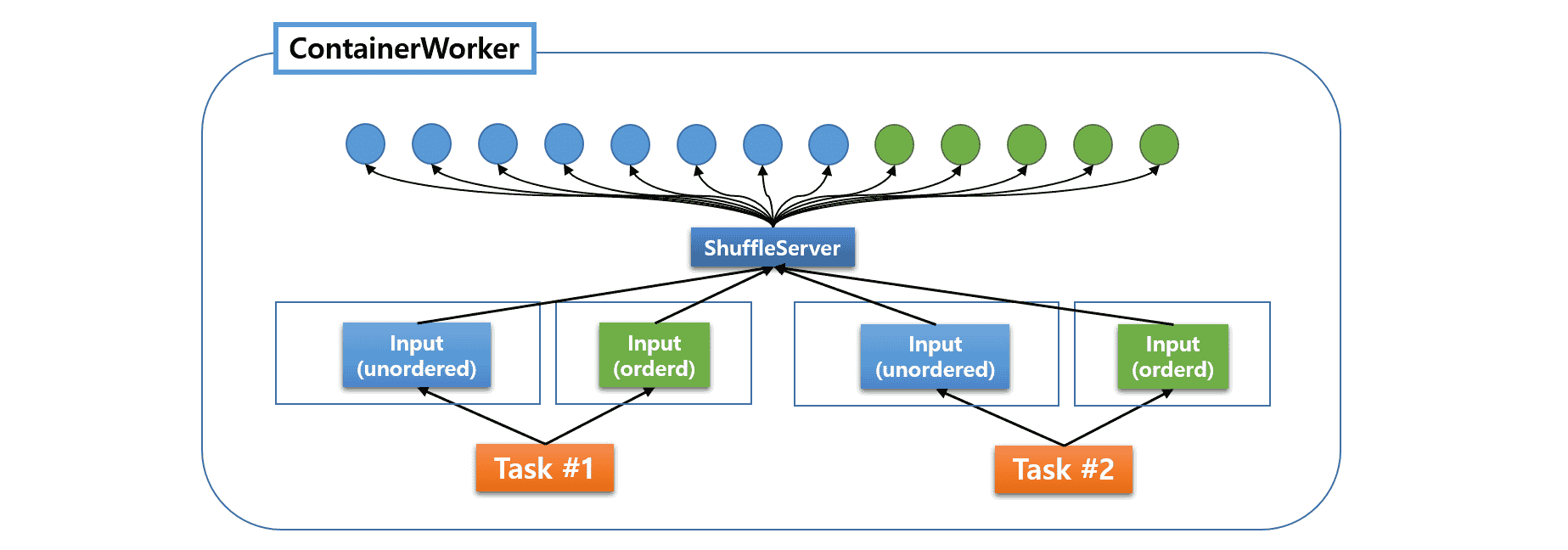
所有 fetcher(有序和无序数据)都由单个 ShuffleServer 创建和管理。ShuffleServer 作为 DaemonTask 实现,在每个 ContainerWorker 中是唯一的。现在我们不仅可以指定单个 LogicalInput 可以请求的最大并发 fetcher 数量,还可以指定在 ContainerWorker 内部运行的最大并发 fetcher 总数。因此,fetcher 的性能通常更稳定,并且为单个 LogicalInput 创建和销毁 ShuffleServer 的(非平凡的)开销现在已经消失了。
在 tez-site.xml 中,配置键 tez.runtime.shuffle.parallel.copies 指定单个 LogicalInput 可以请求的最大并发 fetcher 数量,配置键 tez.runtime.shuffle.total.parallel.copies 指定在 ContainerWorker 内部运行的 fetcher 总数。