消除 Fetch 延迟
Fetch 延迟
Fetch 延迟是一种现象,指在 TCP 监听队列无法处理突发连接请求后,ContainerWorker 之间 shuffle 中间数据长时间卡住(但最终会完成)。它们可能发生在任何为数据传输打开 TCP 监听队列的应用程序中,例如 Hadoop DataNode 守护进程、Hadoop shuffle 服务器和 MR3 shuffle handler。在 MR3 的上下文中,Fetch 延迟会产生慢任务,这些慢任务通常会使 DAG 的完成延迟数百秒,有时甚至数千秒。
以下示例显示了在 42 个节点(每个节点 96GB 内存)的集群中使用 1TB 规模因子运行 TPC-DS 基准测试的查询 4 时的 Fetch 延迟和由此产生的慢任务。在正常情况下,查询在远小于 100 秒的时间内完成,但即使在 124 秒时,Map 7 的四个 Task 仍在运行: 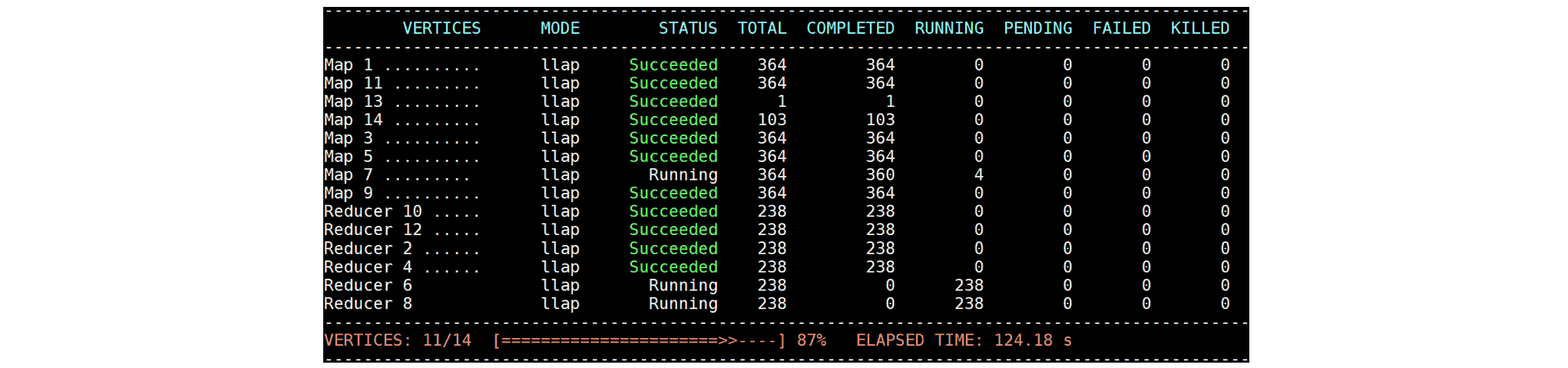 这四个 Task 在接下来的 1400 秒内没有取得任何进展,并使整个查询的进度停滞:
这四个 Task 在接下来的 1400 秒内没有取得任何进展,并使整个查询的进度停滞: 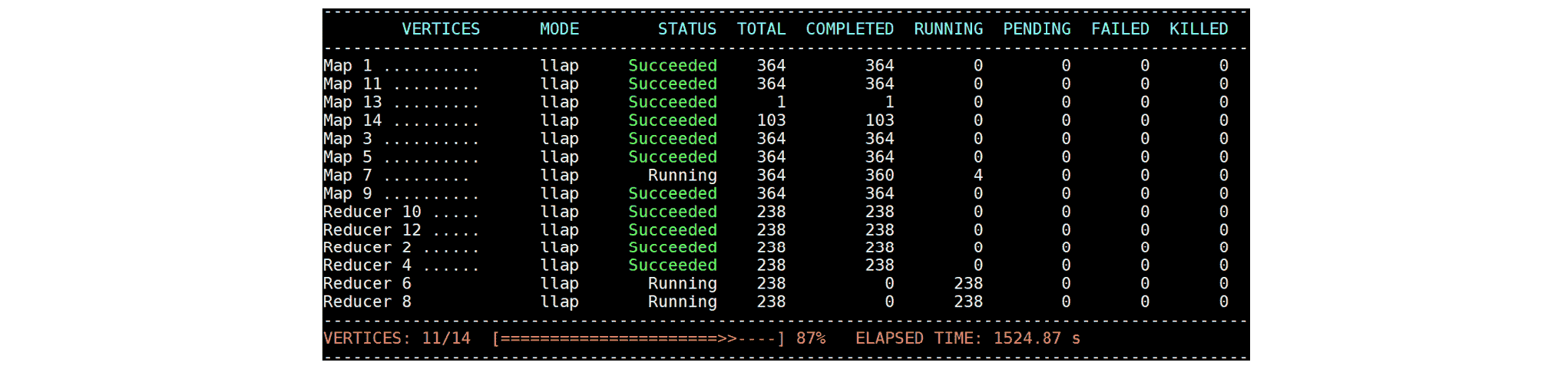 在这些慢任务恢复之前,集群中的每个节点都保持空闲,因为来自 Map 13 和 Map 14 的数据传输是瓶颈。(Map 7 不仅从 HDFS 读取,还从 Map 13 和 Map 14 生成的中间数据读取。)最终查询在 1577 秒时完成,但在导致整个集群停滞超过 1400 秒之后。
在这些慢任务恢复之前,集群中的每个节点都保持空闲,因为来自 Map 13 和 Map 14 的数据传输是瓶颈。(Map 7 不仅从 HDFS 读取,还从 Map 13 和 Map 14 生成的中间数据读取。)最终查询在 1577 秒时完成,但在导致整个集群停滞超过 1400 秒之后。
具有讽刺意味的是,Fetch 延迟更频繁地发生在 1)小数据集而不是大数据集,以及 2)大数据集而不是小数据集上。对于数据集大小而言,直观上,大型集群可以容纳更多的 Task,小数据集允许 Task 更快地完成。因此,许多 Task 可以同时向公共数据源发出突发连接请求,从而增加 Fetch 延迟的机会。在我们的实验中,例如,查询 4 在 1TB 数据集上非常频繁地遭受 Fetch 延迟,但在 10TB 数据集上从未遭受。DAG 的结构(例如在 HivePlus 中编译查询的结果)也会影响 Fetch 延迟的机会。在我们的实验中,例如,TPC-DS 基准测试中只有查询 4 会产生 Fetch 延迟。
在 MR3 中消除 Fetch 延迟
info
在 MR3 中,Fetch 延迟主要通过背压和推测获取来解决。如果尽管进行了推测获取,Fetch 延迟仍然存在,以下策略可能会有所帮助。
我们结合 MR3 的两个特性来解决 Fetch 延迟问题。
- 我们在一个 ContainerWorker 中运行多个 shuffle handler,以减少 Fetch 延迟的机会(请参阅 MR3 Shuffle Handler)。我们可以将使用多个 shuffle handler 视为实现了一种简单形式的负载均衡。需要注意的是,运行多个 shuffle handler 与通过调整
tez-site.xml中的配置参数tez.shuffle.max.threads在单个 shuffle handler 中运行多个工作线程是不同的。 - 为了在发生 Fetch 延迟时减轻慢任务的影响,我们使用推测执行(请参阅推测执行)。也就是说,当 MR3 检测到慢任务时,它会创建另一个 TaskAttempt,希望新的 TaskAttempt 不会遭受 Fetch 延迟。如果新的 TaskAttempt 后来也被判断为慢任务,MR3 会创建另一个 TaskAttempt,依此类推。
下面我们演示 MR3 如何消除 Fetch 延迟。我们在上述相同设置中连续运行 TPC-DS 基准测试的查询 4 总共 100 次,并报告每次运行的执行时间。
-
如果我们 1)在每个节点上部署一个大型 ContainerWorker,2)在每个 ContainerWorker 中创建一个 shuffle handler,以及 3)不使用推测执行,Fetch 延迟会频繁发生。在这种情况下,每个节点上只有一个 shuffle handler 在运行。图表显示 x 轴为运行号,y 轴为执行时间(秒)。
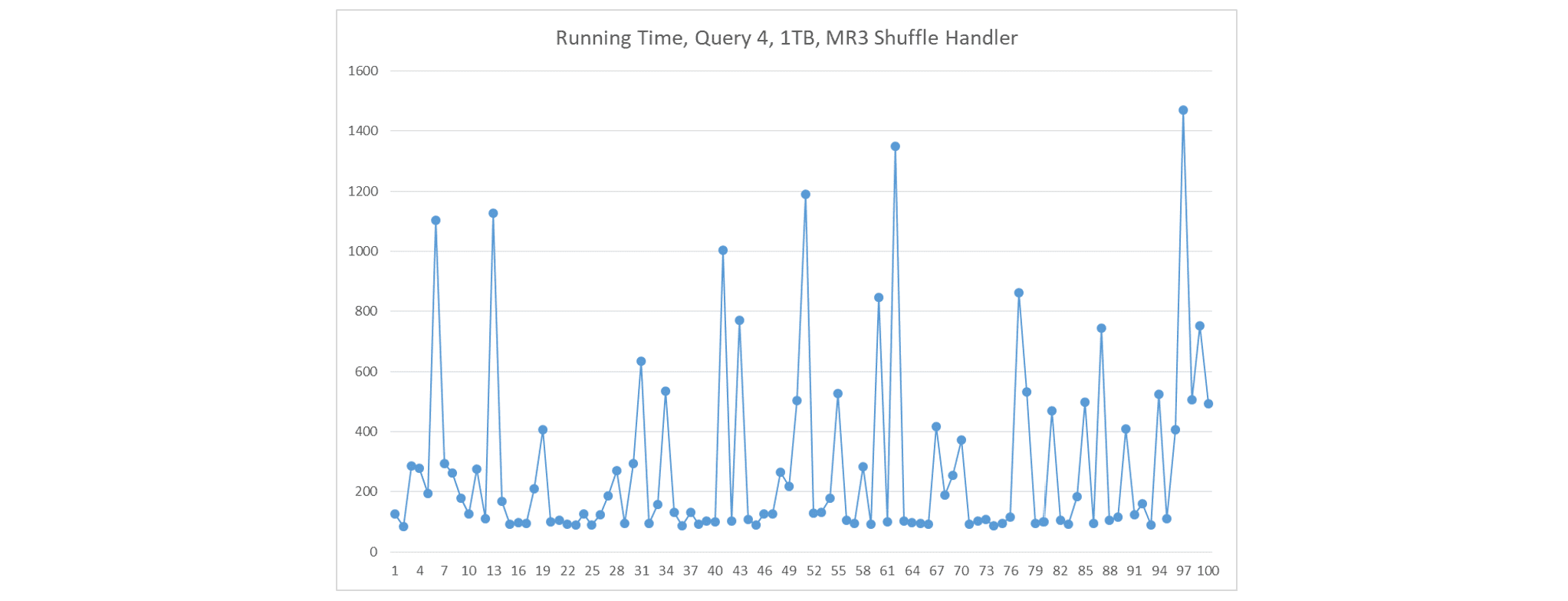
-
如果我们改用 Hadoop shuffle 服务(在每个节点上作为独立进程运行),Fetch 延迟发生的频率较低,但仍是一个严重问题。
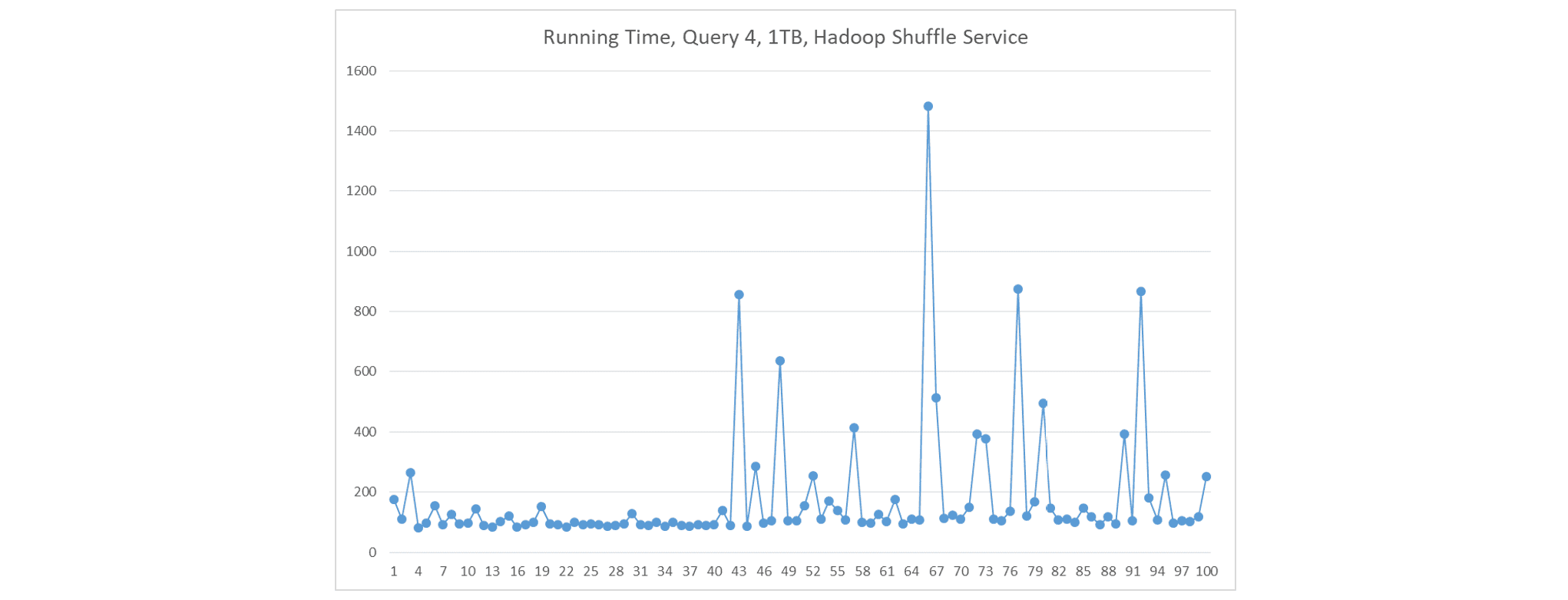
-
如果我们 1)在每个节点上部署 5 个小型 ContainerWorker,2)在每个 ContainerWorker 中创建一个 shuffle handler,以及 3)不使用推测执行,Fetch 延迟发生的频率要低得多。结果比第一种情况好,因为每个节点运行 5 个 shuffle handler。
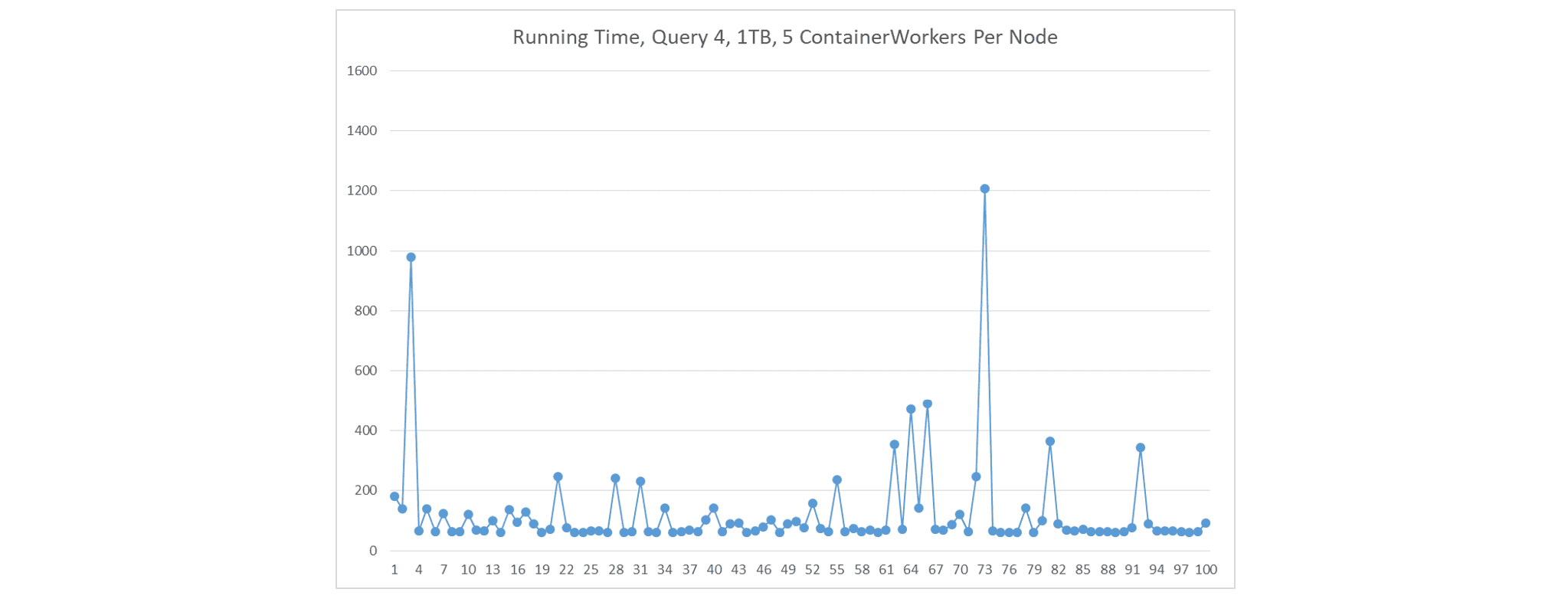
-
如果我们 1)在每个节点上部署一个大型 ContainerWorker,2)在每个 ContainerWorker 中创建 10 个 shuffle handler,以及 3)使用推测执行,Fetch 延迟很少发生。在这种情况下,每个节点上有 10 个 shuffle handler 在运行。
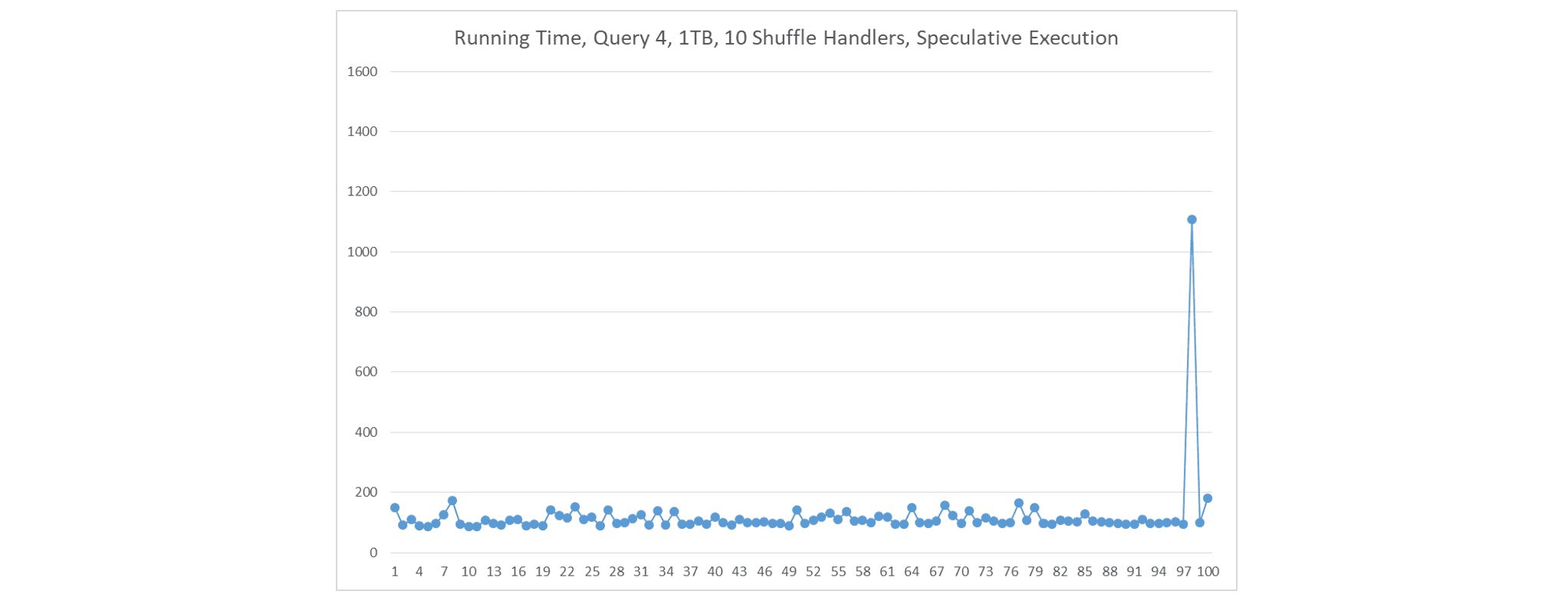
-
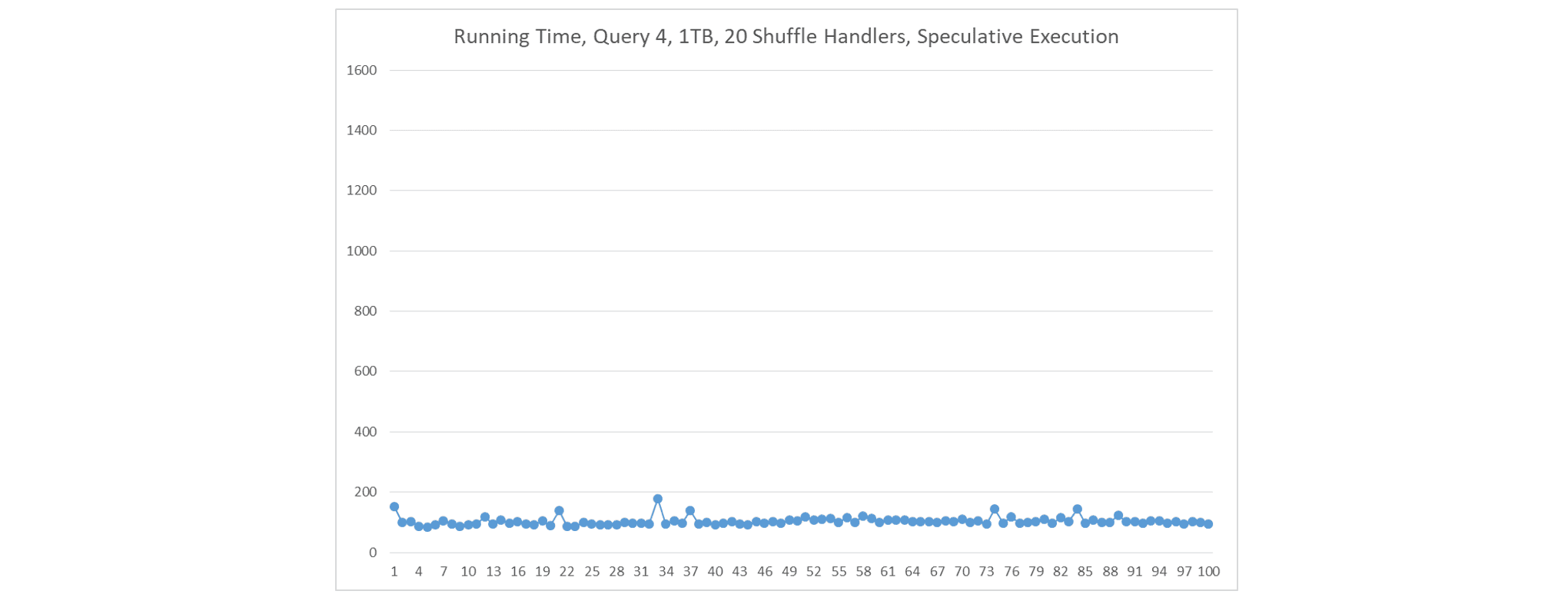
如果我们 1)在每个节点上部署一个大型 ContainerWorker,2)在每个 ContainerWorker 中创建 20 个 shuffle handler,以及 3)使用推测执行,Fetch 延迟从未发生。在这种情况下,每个节点上有 20 个 shuffle handler 在运行。此外,执行时间明显比前一种情况更稳定。