容错
MR3 中的容错
MR3 是一个容错系统,能够从 TaskAttempt 失败中恢复并继续其预期操作。在以下四种情况下,MR3 决定是否从 TaskAttempt 失败中恢复:
- TaskAttempt 因可恢复异常(如
IOException)而失败。 - TaskAttempt 因致命错误(如
OutOfMemoryError和 HivePlus 中的MapJoinMemoryExhaustionError)而失败。 - TaskAttempt 被杀死。
- TaskAttempt 正常操作,但由于 fetch 失败而无法读取源 TaskAttempt 的输出(其中消费者'无法'从远程节点'获取'生产者的输出)。
在每种情况下,MR3 要么使相应的 Task(及其 Vertex,最终是整个 DAG)失败,要么通过重新调度新的 TaskAttempt 来继续。对于每个 Task,MR3 跟踪应被视为有效尝试的 TaskAttempt 总数,并确保其永远不会超过配置键 mr3.am.task.max.failed.attempts 指定的阈值(默认值为 3)。例如,当 mr3.am.task.max.failed.attempts 设置为 3 时,一个 Task 最多可以尝试 3 个独立的 TaskAttempt。
在情况 1 中,MR3 简单地重新调度一个新的 TaskAttempt 并继续。
在情况 2 中,MR3 的行为取决于为配置键 mr3.am.task.no.retry.errors 和 mr3.am.task.retry.on.fatal.error 设置的值。如果错误在 mr3.am.task.no.retry.errors 指定的列表中找到,MR3 会使相应的 Task 失败,进而使整个 DAG 失败。如果未找到,MR3 会检查 mr3.am.task.retry.on.fatal.error 的值。如果设置为默认值 false,MR3 会使相应的 Task 失败,进而使整个 DAG 失败。如果设置为 true,MR3 会重新调度一个新的 TaskAttempt 并继续。
在 HivePlus 中,情况 2 中继续执行 Task 对于完成那些即使使用 Hive 中可用的查询重新执行机制也会失败的查询很有用。也就是说,用户可能能够完成一个即使使用查询重新执行也会失败的查询。这是因为通过即使在致命错误上也重试,Hive 可能能够收集更准确的输入数据统计信息。另一方面,如果查询在查询重新执行时成功,则快速失败 Task 会减少总执行时间。
在情况 3 中,MR3 会重新调度一个新的 TaskAttempt,但不会将先前的 TaskAttempt 计为有效尝试。这是因为 TaskAttempt 被 MR3 本身杀死(例如,MR3 抢占运行的 TaskAttempt 以避免 Vertex 之间的死锁)、被用户杀死(例如,用户杀死 ContainerWorker 进程)或被底层系统杀死(例如,操作系统杀死 ContainerWorker 进程,或节点崩溃)。本质上,TaskAttempt 被杀死不是因为其自身的过错,而是因为外部因素。
在情况 4 中,MR3 会重新调度一个新的源 TaskAttempt 以重新生成输出,而抱怨 fetch 失败的 TaskAttempt 继续运行。由于先前源 TaskAttempt 的 Task 已经成功完成,其状态通常从 Succeeded 转换回 Running,从而产生一种称为 Task 重新运行 的现象。如果先前源 TaskAttempt 的 Vertex 已经成功完成,我们还会观察到一种称为 Vertex 重新运行 的现象。需要注意的是,新的源 TaskAttempt 也可能遇到 fetch 失败,此时 MR3 会重新调度另一轮 TaskAttempt。因此,单个 fetch 失败可能触发 Task/Vertex 重新运行的级联,这种情况通常发生在节点崩溃时。
实现 Task/Vertex 重新运行
由于在从 fetch 失败恢复时 Task 和 Vertex 中的状态转换复杂,情况 4 中的 Task/Vertex 重新运行是最难忠实实现的挑战。事实上,事实证明,并非每个普遍认为支持容错的执行引擎都完全实现了从 fetch 失败中恢复的逻辑。例如,以下问题在 Tez 中仍未解决(截至 2025 年 3 月):
Task/Vertex 重新运行的正确实现对于 Kubernetes 和云环境尤其重要,因为在这些环境中,逻辑节点可以频繁出现和消失。例如,用户可以选择使用可抢占实例在公共云上运行 MR3,这些实例可以随时被抢占。如果包含活动 DAG 中间数据的节点停用,MR3 可以通过其 Task/Vertex 重新运行的实现成功完成 DAG。
在 Hadoop 的情况下,Task/Vertex 重新运行不太可能发生,因为物理节点不会经常崩溃。在 ContainerWorker 进程崩溃或被杀死的情况下,我们也可以通过使用 Hadoop shuffle 服务来避免 fetch 失败,因为每个节点上始终有 Hadoop shuffle 服务可用。但是,如果 MR3 使用自己的内置 shuffle handler 运行,则应在发生 fetch 失败时激活 Task/Vertex 重新运行。
示例
以下示例演示了 MR3 在不使用 Hadoop shuffle 服务的 Hadoop 集群上运行时的容错特性。在 33 秒时,我们看到所有 Map Vertex 都成功了: 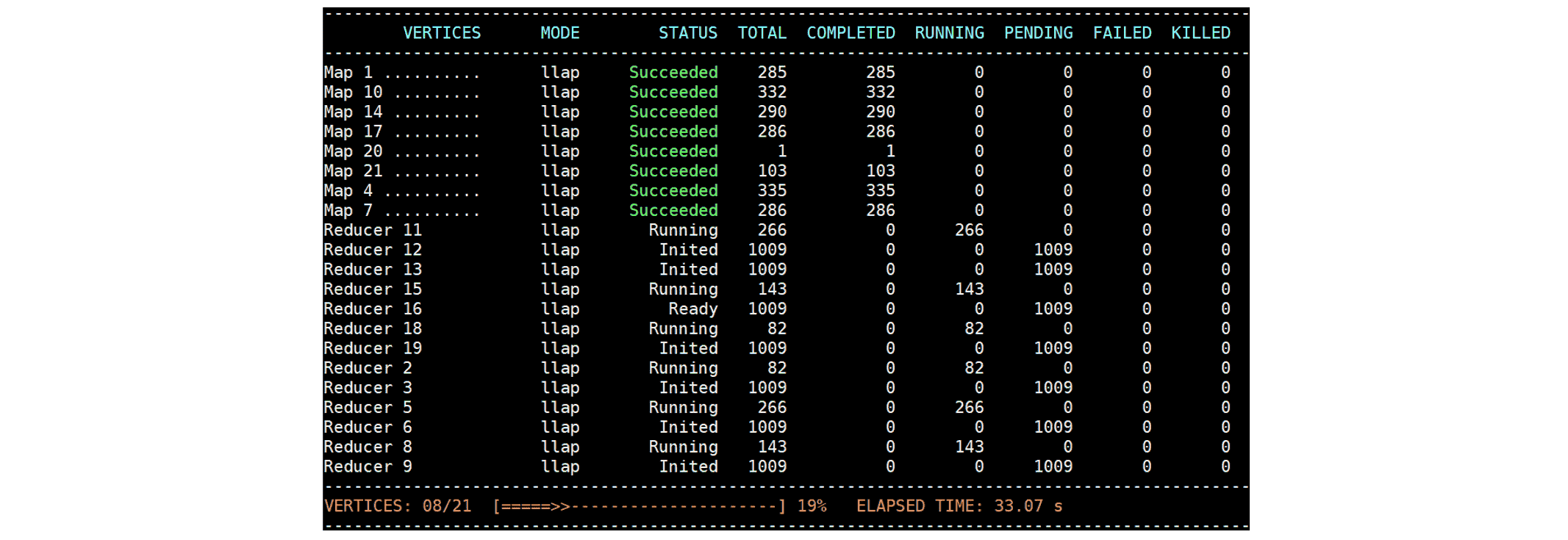 然后我们从总共 10 个 ContainerWorker 中杀死一个 ContainerWorker。我们观察到两个 Map Vertex(Map 21 和 Map 4)转换回
然后我们从总共 10 个 ContainerWorker 中杀死一个 ContainerWorker。我们观察到两个 Map Vertex(Map 21 和 Map 4)转换回 Running: 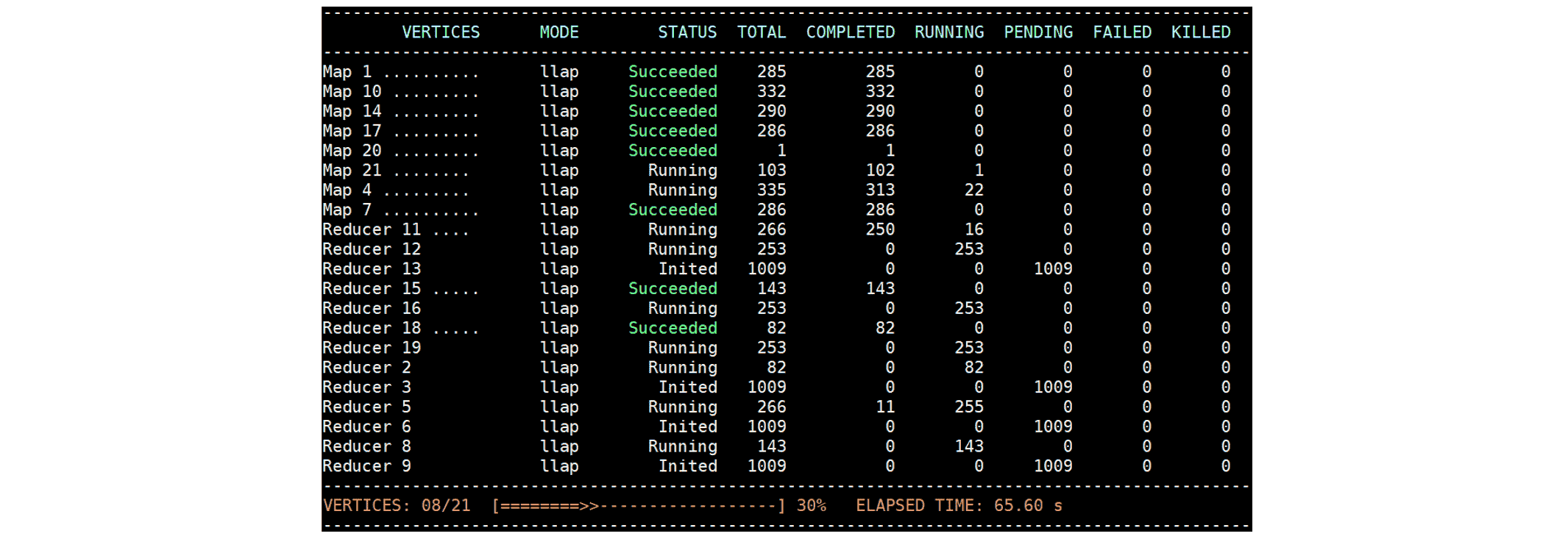 我们还观察到 Reducer 5 和 Reducer 11 的运行 TaskAttempt 被杀死,以防止死锁:
我们还观察到 Reducer 5 和 Reducer 11 的运行 TaskAttempt 被杀死,以防止死锁: 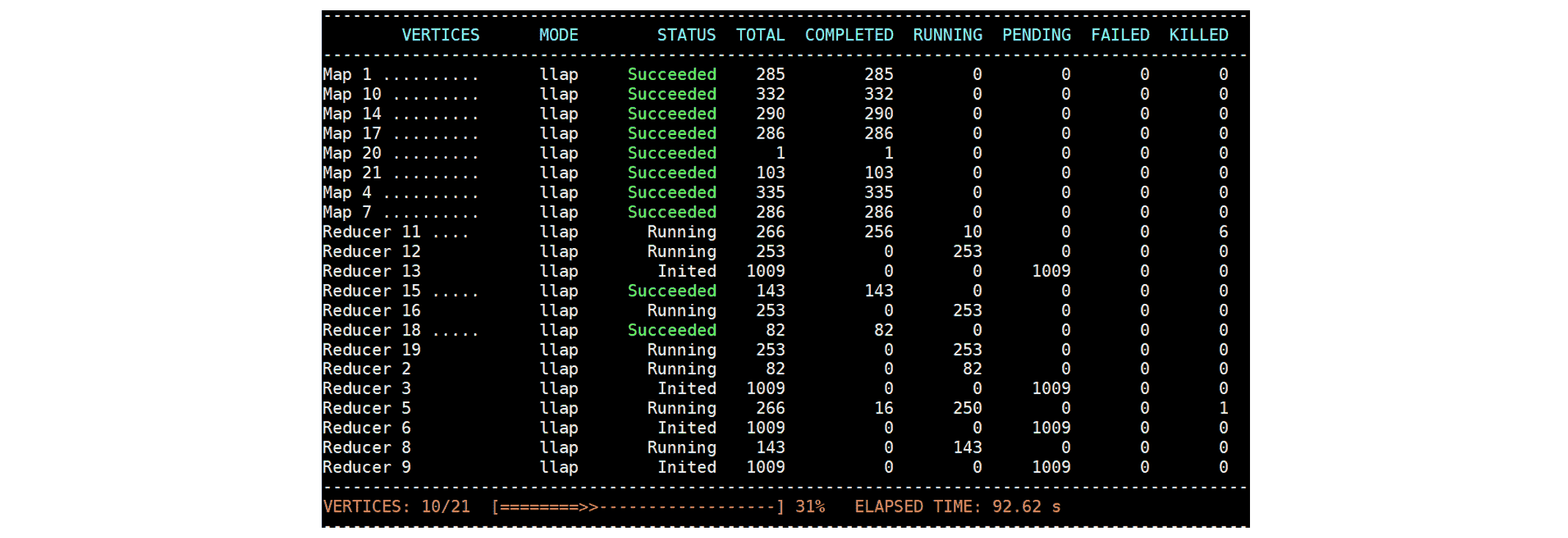 最终 DAG 成功完成。
最终 DAG 成功完成。