DAG/Task 调度
为了最大化吞吐量(即每单位时间完成的查询数量)或最小化周转时间(即从接受查询到完成查询的时间),MR3 提供了一种复杂的方案,用于调度和执行来自不同 DAG 的 Task。MR3 内部在将 Task 发送到 ContainerWorker 执行之前经过三个阶段:
- 使用 DAGScheduler 将 DAG 映射到 Task 队列
- 为 Task 分配优先级
- 使用 TaskScheduler 在每个 Task 队列中调度 Task
1. DAG 调度
MR3 DAGScheduler 使用配置键 mr3.dag.queue.scheme 将 DAG 分配到 Task 队列。默认值为 common。
common(默认):DAGScheduler 为所有 DAG 使用一个公共 Task 队列。individual:DAGScheduler 为每个单独的 DAG 创建一个 Task 队列。capacity:DAGScheduler 使用容量调度。
如果 mr3.dag.queue.scheme 设置为 individual,DAGScheduler 会尝试从当前消耗资源最少(以内存计)的 DAG 中调度 Task。通过这种方式,MR3 会尽最大努力为所有活动的 DAG 分配相同数量的资源。由于新 DAG 会立即分配其公平份额的资源,而旧 DAG 不会因其长时间运行而受到惩罚,因此在并发环境中 DAG 的执行时间是可预测的。例如,如果一个 DAG 在没有并发 DAG 的情况下在 100 秒内完成,那么在 9 个相同结构的并发 DAG 下,它有相当大的机会在约 100 × 10 = 1000 秒内完成。
在并发环境中,将 mr3.dag.queue.scheme 设置为 common 通常比设置为 individual 能实现更高的吞吐量。这是因为为增加中间数据的时间局部性而实现的优化在 MR3 被允许一次分析所有 DAG 的 Task 依赖关系时效果最佳。例如,当 Task 的整个输入变得可用时,MR3 可能决定立即调度它,即使存在许多更高优先级的 Task。然而,如果 mr3.dag.queue.scheme 设置为 individual,优化效果会差得多,因为 MR3 只能分析属于同一 DAG 的 Task 之间的依赖关系。总之,将 mr3.dag.queue.scheme 设置为 common 使 MR3 能够全局优化所有 DAG 的执行,而设置为 individual 则不能。
容量调度
如果 mr3.dag.queue.scheme 设置为 capacity,MR3 DAGScheduler 通过管理具有不同优先级和容量要求的多个 Task 队列来使用容量调度。用户使用另一个配置键 mr3.dag.queue.capacity.specs 指定容量调度策略。每个条目由 Task 队列的名称和最小容量百分比组成。Task 队列按优先级顺序指定。
作为一个例子,将 mr3.dag.queue.capacity.specs 设置为 high=80,medium=50,default=20,background=0 的解释如下。
- MR3 按优先级顺序创建四个 Task 队列(
high、medium、default、background)。也就是说,Task 队列high被分配最高优先级,而 Task 队列background被分配最低优先级。 - Task 队列
high保证获得 80% 的资源。但是,未被high占用的空闲资源可以分配给优先级较低的 Task 队列。 - 如果
high消耗不超过 50% 的资源,则 Task 队列medium保证获得 50% 的资源。 - 如果
high和medium消耗不超过 80% 的资源,则 Task 队列default保证获得 20% 的资源。 - Task 队列
background保证不获得任何资源。因此,它只在没有其他 Task 队列请求资源时才消耗资源。
作为另一个例子,假设 mr3.dag.queue.capacity.specs 设置为 high=40,medium=20,default=10,background=0。在满足 high、medium 和 default 的容量要求后,仍有 30% 的资源剩余。在这种情况下,MR3 首先将剩余资源分配给优先级较高的 Task 队列。因此,只要其他优先级较高的 Task 队列请求剩余 30% 的资源,Task 队列 background 就不会被分配任何资源。
作为一条特殊规则,如果未指定 Task 队列 default,MR3 会自动将 default:0 附加到 mr3.dag.queue.capacity.specs 的值。例如,foo=80,bar=20 会自动扩展为 foo=80,bar=20,default=0。因此,在容量调度下,Task 队列 default 始终可用。
DAG 使用配置键 mr3.dag.queue.name 指定其 Task 队列(仅在容量调度下有效)。如果 DAG 选择不存在的 Task 队列或未指定其 Task 队列,则会分配给 Task 队列 default。
DAGScheduler 定期记录容量调度的状态(默认每 10 秒一次)。在以下示例中,我们看到 Task 队列 high 消耗了 36% 的资源,有 208 个待处理的 TaskAttempt。
2022-08-12T09:10:48,635 INFO [All-In-One] TaskAttemptQueue$: DAGScheduler All-In-One 2211840MB: high = 208/36%, medium = 2371/43%, default = 169/20%, background = 856/0%
MR3 永远不会抢占运行在较低优先级 Task 队列中的 TaskAttempt,以找到较高优先级 Task 队列请求的资源。因此,即使具有最高优先级的 Task 队列也可能需要等待一段时间,如果所有资源都被较低优先级的 Task 队列使用的话。
2. 分配 Task 优先级
在 MR3 中,Task 的优先级由 1)其 DAG 的优先级和 2)其 Vertex 的优先级决定,其中 DAG 优先级优先于 Vertex 优先级。例如,具有较高 DAG 优先级的 Task 比具有较低 DAG 优先级的 Task 优先级更高,无论其 Vertex 优先级如何。对于具有相同 DAG 优先级的 Task,TaskScheduler 会考虑其 Vertex 优先级。
MR3 使用配置键 mr3.dag.priority.scheme 分配 DAG 优先级。默认值为 fifo。
fifo(默认):MR3 按顺序分配 DAG 优先级。也就是说,第一个 DAG 被分配 DAG 优先级 0,第二个 DAG 被分配 DAG 优先级 1,依此类推。concurrent:MR3 为所有 DAG 分配相同的 DAG 优先级。
info
如果 mr3.dag.queue.scheme 设置为 individual,用户可能会忽略 mr3.dag.priority.scheme,因为每个 DAG 都维护自己的 Task 队列。
MR3 使用另一个配置键 mr3.vertex.priority.scheme 来更新 Vertex 优先级。配置键 mr3.vertex.priority.scheme 的解释如下。
intact:MR3 不更新 DAG 中已指定的 Vertex 优先级。roots:MR3 根据与读取输入数据的根 Vertex 的距离重新计算 Vertex 优先级。leaves:MR3 根据到产生输出数据的叶 Vertex 的距离重新计算 Vertex 优先级。postorder(默认):MR3 根据 DAG 的后序遍历重新计算 Vertex 优先级。normalize:MR3 将 Vertex 优先级规范化为 0 到 12252240(2^4 * 3^2 * 5 * 7 * 11 * 13 * 17,一个高度复合数)之间的范围。
roots/leaves/postorder/normalize 的精确定义比看起来要复杂得多,因为通常 DAG 不是单根树。下面通过一个例子来说明如何为同一 DAG 中的 Vertex 分配优先级。下图显示了为 HivePlus 从 TPC-DS 基准测试的查询 44 生成的 DAG 分配 Vertex 优先级的结果。需要注意的是,在 postorder 的情况下,所有 Vertex 具有不同的优先级。
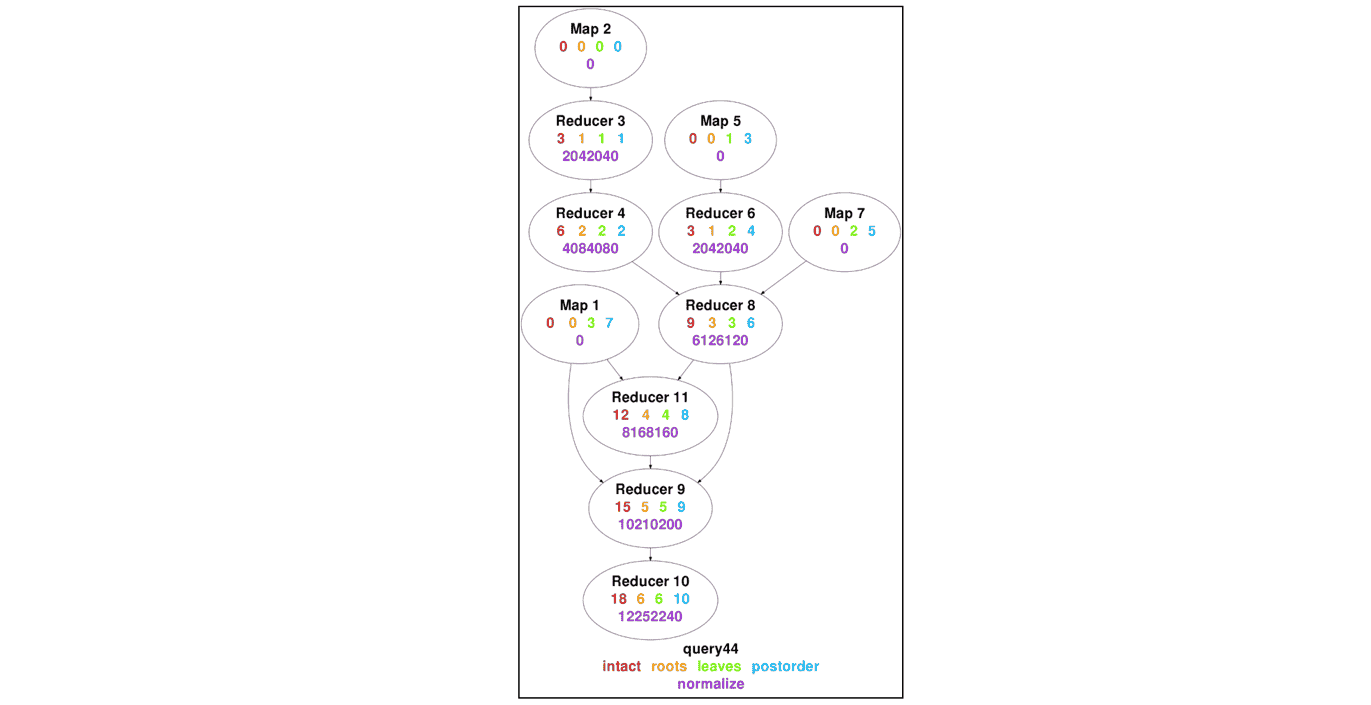
mr3.vertex.priority.scheme 的默认值是 postorder,因为它通常能实现最高的吞吐量。直观上,postorder 尝试在一个 Task 的所有生产者 Task 完成后立即执行该 Task,从而增加 Task 之间 shuffle 的中间数据的时间局部性。
实验 1. 每个 Beeline 客户端提交相同的查询集。
在第一个实验中,我们运行 16 个 Beeline 客户端,每个客户端提交 17 个查询,即 TPC-DS 基准测试中的查询 25 到查询 40。(TPC-DS 基准测试的规模因子为 10TB。)按顺序执行时,这些查询平均在 46 秒内完成,而运行时间最长的查询需要约 110 秒。为了更好地模拟真实环境,每个 Beeline 客户端以独特的顺序提交这 17 个查询。
下图显示了每个 Beeline 客户端的进度(y 轴表示经过的时间)。每种颜色对应所有 Beeline 客户端中的一个唯一查询。
- 我们将
mr3.dag.queue.scheme设置为common。 - 标记为
fifo的图将mr3.dag.priority.scheme设置为fifo,将mr3.vertex.priority.scheme设置为intact。 - 每个剩余的图将
mr3.dag.priority.scheme设置为concurrent,将mr3.vertex.priority.scheme设置为其标签。
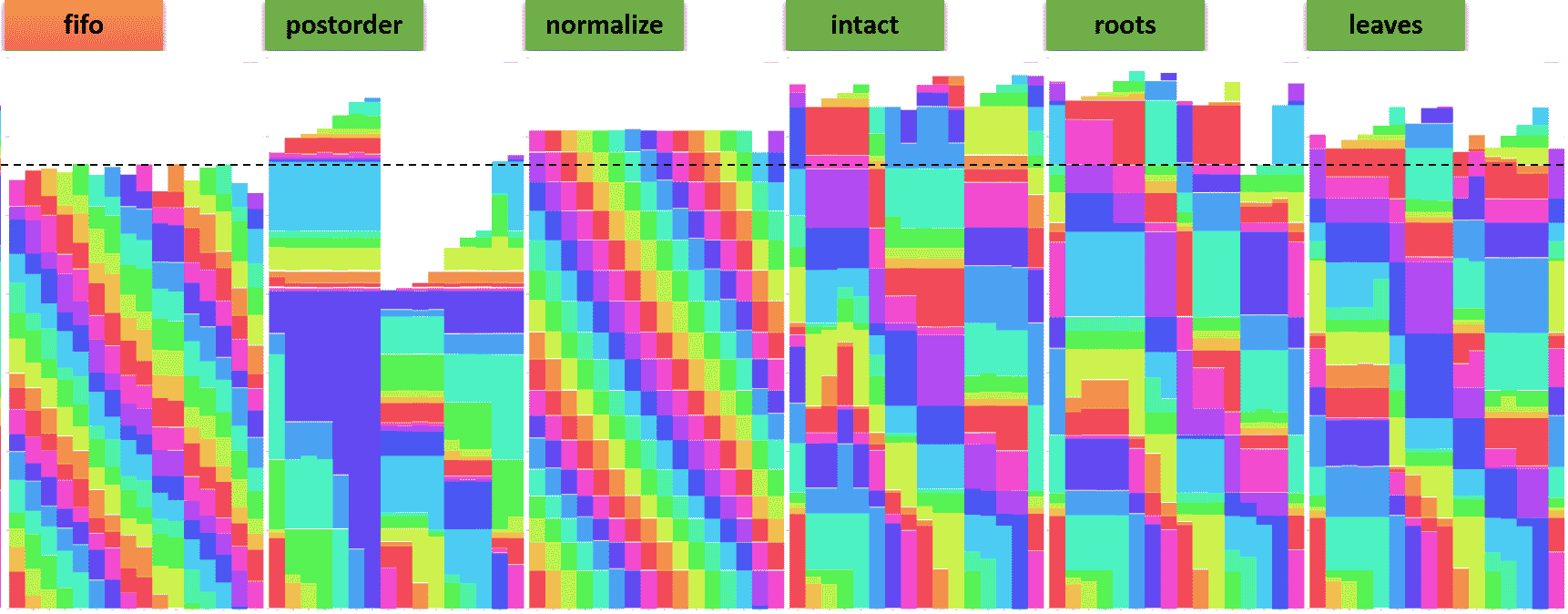
我们得出以下观察结果:
- 将
mr3.dag.priority.scheme设置为fifo可获得最短的运行时间,即最高的吞吐量。 - 将
mr3.vertex.priority.scheme设置为postorder会导致最低的总资源消耗。
实验 2. 每个 Beeline 客户端重复提交一个唯一的查询。
在第二个实验中,我们运行 8 个 Beeline 客户端,每个客户端从 TPC-DS 基准测试中提交一个唯一查询,总共 10 次。(TPC-DS 基准测试的规模因子为 10TB。)下表显示了 8 个查询的属性。我们可以将 Beeline 1 和 2 视为执行短时间运行的交互式作业,将 Beeline 7 和 8 视为执行长时间运行的 ETL 作业。
| Beeline | 查询 | Vertex 数量 | 顺序运行时的执行时间(秒) |
|---|---|---|---|
| Beeline 1(最左边,红色) | Query 91 | 9 | 5.479 |
| Beeline 2 | Query 3 | 4 | 24.959 |
| Beeline 3 | Query 57 | 10 | 36.549 |
| Beeline 4 | query 30 | 11 | 52.502 |
| Beeline 5 | query 5 | 18 | 77.906 |
| Beeline 6 | query 29 | 13 | 99.199 |
| Beeline 7 | query 50 | 9 | 273.457 |
| Beeline 8(最右边,粉色) | query 64 | 31 | 424.751 |
下图显示了每个 Beeline 客户端的进度。
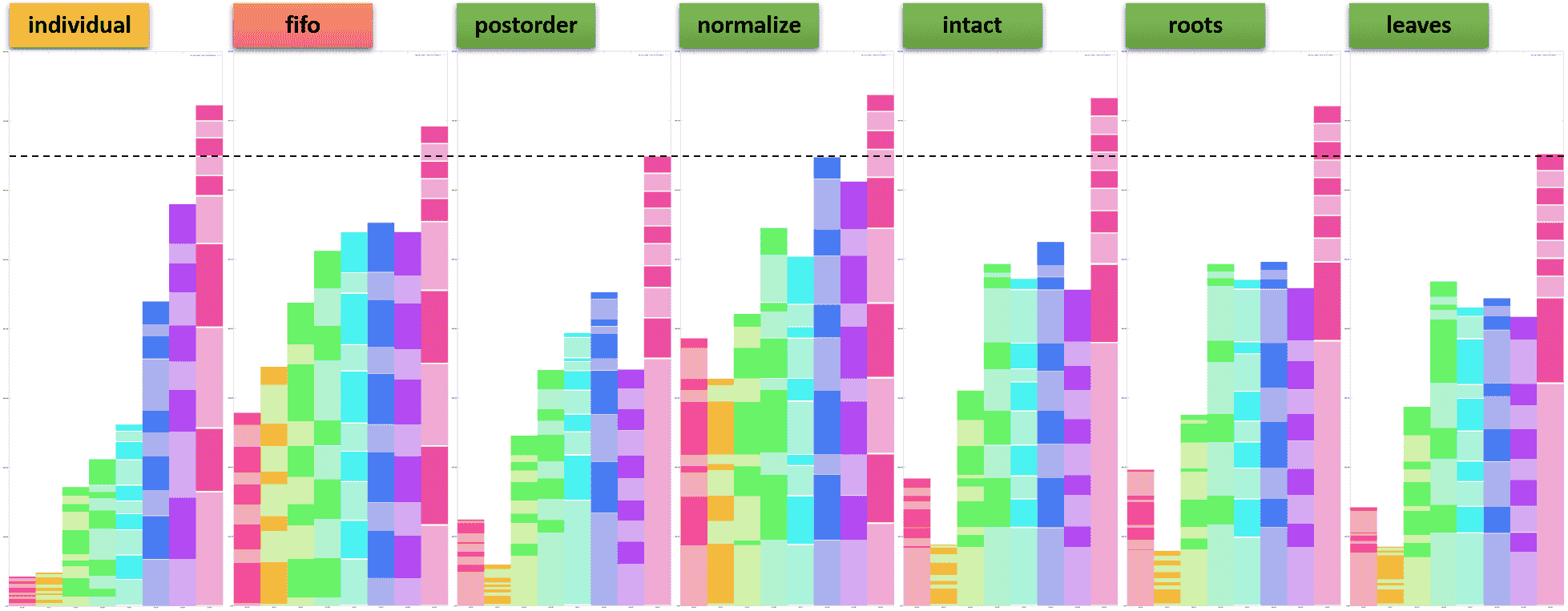
我们得出以下观察结果。
- 将
mr3.dag.queue.scheme设置为individual可以实现最公平的 Beeline 客户端资源分配,因为 Beeline 客户端的总执行时间与顺序运行时其查询的执行时间大致成比例。需要注意的是,将mr3.dag.priority.scheme设置为concurrent并将mr3.vertex.priority.scheme设置为normalize会产生完全不同的结果。例如,每个 Beeline 客户端在第一次执行其查询时花费的时间大致相同。 - 如果
mr3.dag.priority.scheme设置为concurrent,将mr3.vertex.priority.scheme设置为postorder会同时产生最高的吞吐量和最短的周转时间。将mr3.vertex.priority.scheme设置为leaves是第二好的选择。
3. Task 调度
Task 队列与 MR3 TaskScheduler 的唯一实例相关联。当 ContainerWorker 发送具有特定资源限制(CPU 核数和内存)的请求时,TaskScheduler 在 Task 队列中搜索静态资源需求不超过提供限制的最高优先级 Task。实际上,它不仅考虑 Task 优先级,还考虑 Task 的位置提示。它偶尔可能会忽略 Task 优先级以提高资源利用率,甚至可以动态修改 Task 优先级以防止死锁。
考虑到设计高效调度器的独特挑战(来自不同 DAG 的 Task 可以在 ContainerWorker 中混合),TaskScheduler 利用一种称为生产者完整性的动态属性来最大化资源利用率。生产者完整性是 Vertex 的一个属性,指示其所有生产者 Vertex 是否已完成。也就是说,当所有生产者 Vertex 完成执行其 Task 时,Vertex 变得生产者完整。(根据定义,没有传入边的 Vertex 从一开始就是生产者完整的。)
执行生产者不完整的 Task,即尚未生产者完整的 Task,可能会浪费计算资源,同时等待其输入可用。因此,当 Task 队列中存在生产者完整的 Task 时,TaskScheduler 会避免执行生产者不完整的 Task。这种动态覆盖优先级的策略也增加了 Task 之间 shuffle 的中间数据的时间局部性,进一步提高了效率。另一方面,如果所有生产者完整的 Task 已经在执行中,TaskScheduler 会开始执行剩余的 Task 以避免计算资源空闲。这种策略是有效的,因为一些 Task 即使在其输入仅部分可用时也能取得进展。
TaskScheduler 使用配置键 mr3.taskattempt.queue.scheme 来选择调度 Task 以在 ContainerWorker 中执行的方案。默认方案是 indexed。
basic:TaskScheduler 不使用基于生产者完整性的优化。此方案仅用于性能比较。simple、opt、indexed(默认):TaskScheduler 应用基于生产者完整性的优化。(simple和opt是indexed的早期版本。)spark:TaskScheduler 使用 Spark 风格的方案,其中仅在所有生产者 Task 完成后才调度消费者 Task。
indexed 方案
使用 indexed 方案的 TaskScheduler 还应用了一种优化,以减少慢任务延迟其消费者 Task 的可能性。其思想是,在同一 Vertex 中,具有较大输入数据的 Task 可能比较小输入数据的 Task 需要更长时间才能完成。因此 TaskScheduler 为具有较大输入数据的 Task 分配更高的优先级,以便潜在的慢任务能够更早启动。在以下示例中,两个慢任务(绿色)显著延迟了消费者 Task(蓝色)的进度:

通过更早地调度这样的慢任务,我们可以减轻它们对下游执行的影响。
配置键 mr3.vertex.high.task.priority.fraction 指定在同一 Vertex 内分配更高优先级的 Task 的比例。默认值为 0.05。
严格模式
如果配置键 mr3.taskattempt.queue.scheme.strict 设置为 true,TaskScheduler 以严格模式运行,仅在与位置提示匹配的 ContainerWorker 上调度 Task。相比之下,非严格模式下的 TaskScheduler 在没有匹配的 ContainerWorker 可用时可能会选择忽略位置提示。(没有位置提示的 Task 不受影响。)
由于只有 mapper 可以有位置提示,因此对于启用 LLAP I/O 的 HivePlus(其中读取输入数据较慢或较昂贵,例如当输入数据存储在 Amazon S3 上时),strict 方案特别有用。
配置键 mr3.taskattempt.queue.scheme.strict 仅对 indexed 和 spark 方案有效。