自动伸缩
MR3 中的自动伸缩
MR3 实现了一种请求新 ContainerWorker 和清空现有 ContainerWorker 的机制,以协助云环境中的自动伸缩。它基于 TaskAttempt 在一段时间内消耗的内存来衡量集群的总利用率,并执行两种操作以将总利用率保持在一定范围内。
- Scale-out:当总利用率超过阈值时,MR3 尝试通过向 Hadoop 和 Kubernetes 等集群管理系统发送请求来获取新的 ContainerWorker。
- Scale-in:当总利用率下降到某一点以下时,MR3 清空一定数量的节点,以便集群管理系统可以快速回收这些节点。
在 scale-out 的情况下,集群管理系统通常通过添加可以启动新 ContainerWorker 的新主机来响应。在 scale-in 的情况下,MR3 从为回收而选择的节点中移除所有 ContainerWorker,并且在 scale-in 操作完成之前不会尝试分配新的 ContainerWorker。需要注意的是,scale-out 的单位是 ContainerWorker,而 scale-in 的单位是节点:
- 对于 scale-out,MR3 的自动伸缩机制不知道底层系统,因此只能发送新 ContainerWorker 的请求,而不是新节点的请求。
- 对于 scale-in,MR3 假定底层系统可以检测空闲节点。
一般来说,MR3 不知道单个节点中可以容纳多少个 ContainerWorker。此外,节点可能以不同的内存和 CPU 核数能力添加,MR3 不应对单个节点的能力做出任何假设。
配置自动伸缩
用户可以通过将配置键 mr3.enable.auto.scaling 设置为 true 来启用自动伸缩。在任何时候,每个 ContainerGroup 的调度器都处于三种状态之一:STABLE、SCALE_OUT 和 SCALE_IN。
STABLE:当前总利用率稳定,不需要 scale-out 或 scale-in。SCALE_OUT:调度器已发送新 ContainerWorker 的请求,正在等待集群管理系统的响应。SCALE_IN:调度器已清空一些节点,正在等待固定时间段。
下图显示了自动伸缩中的整体状态转换。图表中的常量由 mr3-site.xml 中的配置键指定。
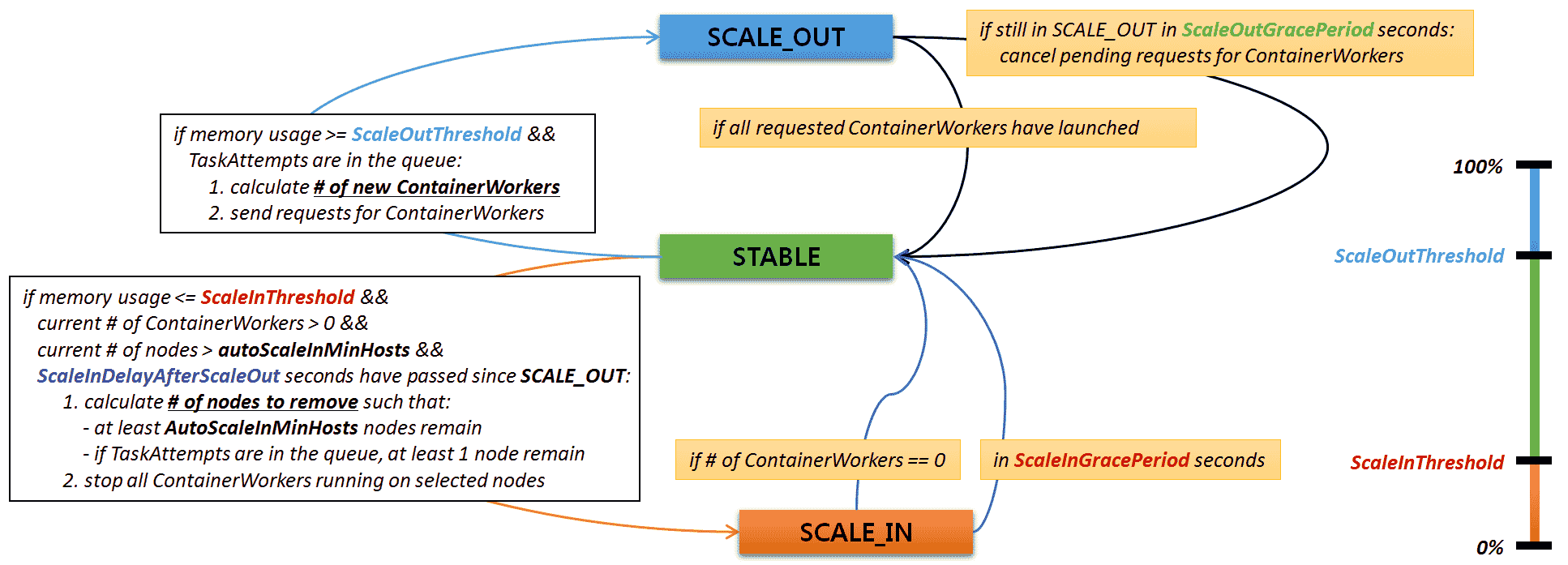
- ScaleOutThreshold =
mr3.auto.scale.out.threshold.percent。触发 scale-out 的最小内存使用百分比。 - ScaleOutGracePeriod =
mr3.auto.scale.out.grace.period.secs。触发 scale-out 后的冷却期(以秒为单位)。冷却期应该比完成 scale-out 操作的平均时间长得多。例如,如果在 Amazon EKS 上创建和初始化新工作节点大约需要 3 分钟,则可以将mr3.auto.scale.out.grace.period.secs设置为 360(相当于 6 分钟)。如果冷却期太短,MR3 可能会过早取消工作节点的配置。 - ScaleInDelayAfterScaleOut =
mr3.auto.scale.in.delay.after.scale.out.secs。触发 scale-in 之前离开 scale-out 后等待的最短时间(以秒为单位)。 - ScaleInThreshold =
mr3.auto.scale.in.threshold.percent。触发 scale-in 的最大内存使用百分比。 - AutoScaleInMinHosts =
mr3.auto.scale.in.min.hosts。执行 scale-in 时应保留的最小节点数。 - ScaleInGracePeriod =
mr3.auto.scale.in.grace.period.secs。触发 scale-in 后的冷却期(以秒为单位)。
近似总利用率
MR3 通过计算内存使用来近似集群的总利用率。在配置键 mr3.check.memory.usage.event.interval.secs 指定的时间间隔,MR3 测量 ContainerWorker 中 TaskAttempt 消耗的内存 fraction。例如,如果有 10 个 ContainerWorker,为 TaskAttempt 分配了 32GB 内存,而总共运行着 40 个 4GB 的 TaskAttempt,我们得到 40 * 4 / 10 * 32 = 50%。然后 MR3 通过在配置键 mr3.memory.usage.check.window.length.secs 指定的时间窗口内累积所有测量值来计算内存使用率,或者取平均值或最大值(由配置键 mr3.memory.usage.check.scheme 指定)。作为实现快速 scale-out 的一个小改进,MR3 排除了在没有运行 ContainerWorker 时进行的测量(例如,集群刚启动后)和在时间窗口头部没有 TaskAttempt 的测量(例如,长空闲期之后)。
Scale-in 和 scale-out
当 MR3 触发 scale-in 操作时(如果配置键 mr3.auto.scale.in.wait.dag.finished 设置为 true),它不会立即终止为回收而选择的节点中运行的所有 ContainerWorker。这是因为这些 ContainerWorker 可能保存着当前活动 DAG 的远程 TaskAttempt 要获取的中间数据。因此,它继续利用这些 ContainerWorker(例如,发送新的 TaskAttempt),直到当前活动的 DAG 全部完成。在 MR3 的实际实现中,它们被设置为在当前活动的 DAG 全部完成时终止自己。
scale-out 请求的 ContainerWorker 数量和 scale-in 清空的节点数量由 mr3-site.xml 中的以下配置键设置:
mr3.auto.scale.out.num.initial.containers,默认值为 0。当当前 ContainerWorker 数量为零时(例如,在执行第一个 DAG 之前创建新鲜的 ContainerWorker 时),它用于快速 scale-out。mr3.auto.scale.out.num.increment.containers,默认值为 0。当一些 ContainerWorker 当前正在运行时使用。mr3.auto.scale.in.num.decrement.hosts,默认值为 0
如果这些键设置为零,MR3 会根据当前内存使用量与 ScaleOutThreshold/ScaleInThreshold 之间的差值计算 ContainerWorker/主机数量。
在 Kubernetes 上,用户可以使用以下配置键设置所有 ContainerWorker Pod 的总资源限制:
mr3.k8s.worker.total.max.memory.gb指定所有 ContainerWorker Pod 的最大内存(GB)。mr3.k8s.worker.total.max.cpu.cores指定所有 ContainerWorker Pod 的最大核心数。