LLAP I/O
DaemonTask 实现 LLAP I/O
HivePlus 支持 LLAP(低延迟分析处理)I/O。如果 ContainerWorker 启用 LLAP I/O 启动,它会用 LlapInputFormat 对象包装每个 HiveInputFormat 对象,以便缓存通过 HiveInputFormat 读取的所有数据。结合在单个 ContainerWorker 内并发执行多个 TaskAttempts 的能力,LLAP I/O 的支持使 HivePlus 在功能上与 Hive-LLAP 等效。
由于 MR3 中已有可用的 DaemonTasks,在 HivePlus 中实现 LLAP I/O 很容易。如果启用了 LLAP I/O,ContainerGroup 会创建一个负责管理 LLAP I/O 的 MR3 DaemonTask。当 ContainerWorker 启动时,会创建一个 DaemonTaskAttempt 来初始化 LLAP I/O 模块。初始化后,LLAP I/O 模块在后台工作,为普通 TaskAttempts 提供服务。
使用 LLAP I/O 的示例
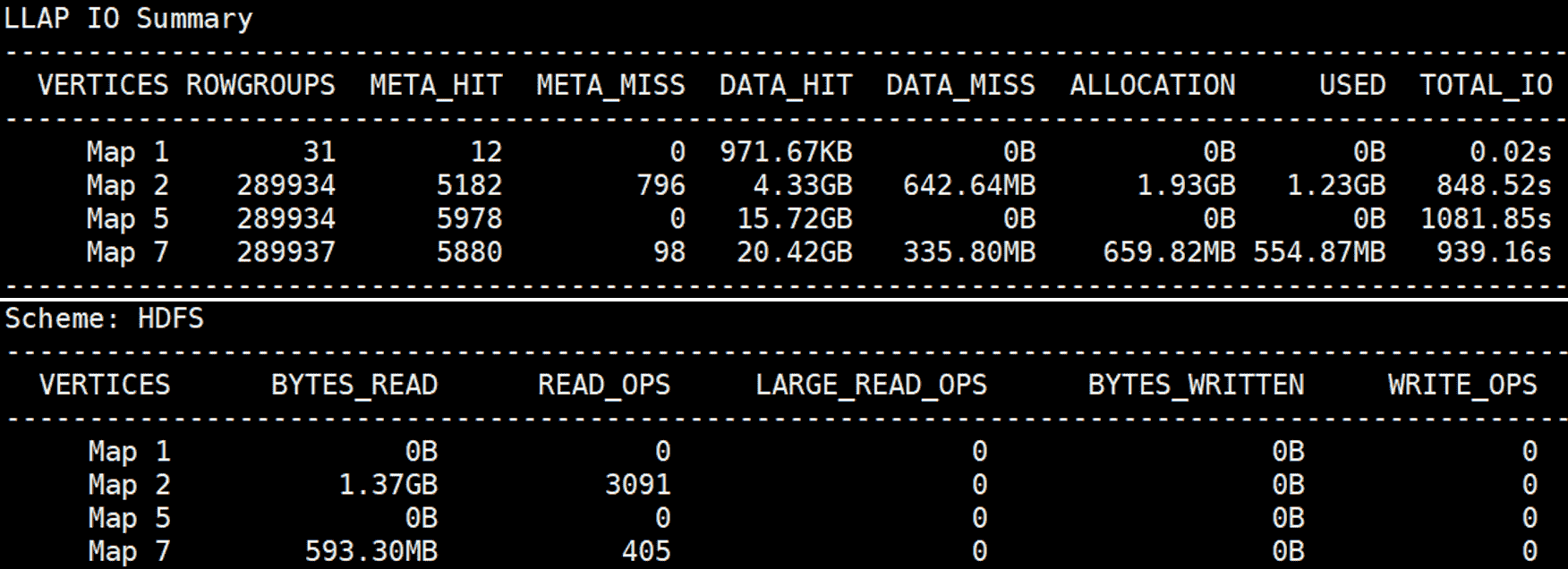
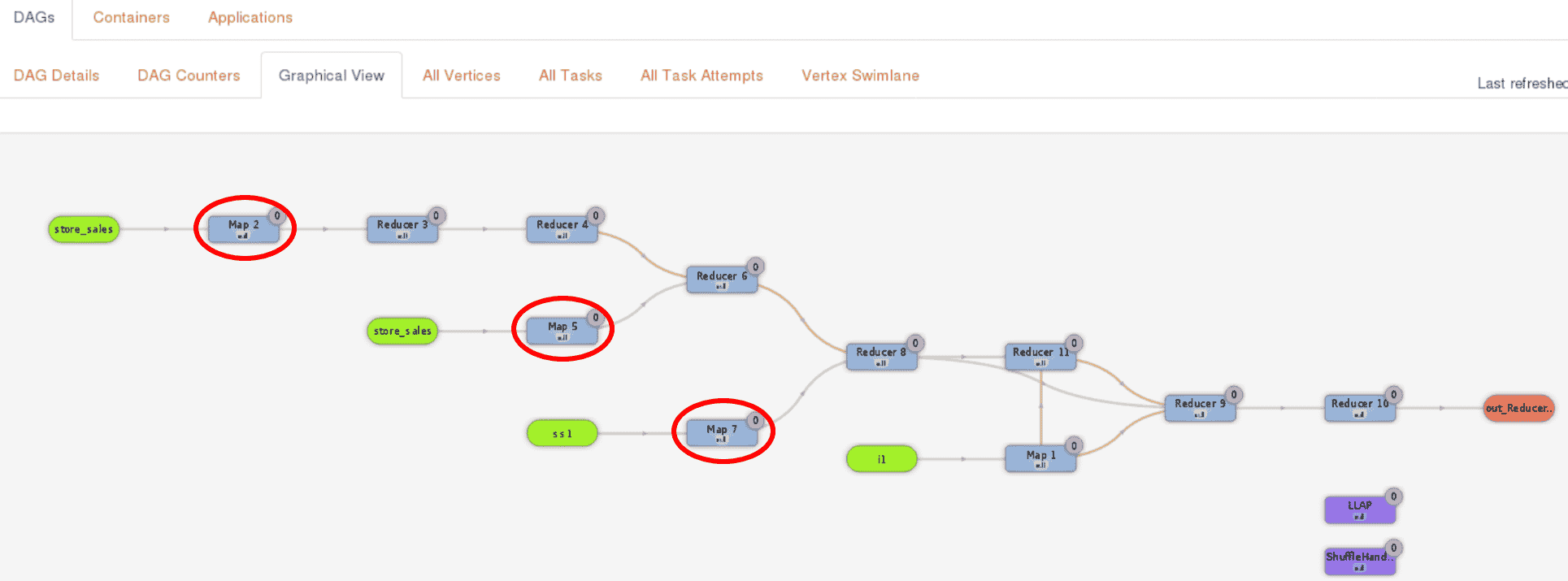
为了说明在 HivePlus 中使用 LLAP I/O 的好处,我们展示了在 1TB 数据集上运行 TPC-DS 基准测试查询 44 的结果。我们使用两个通过 10 Gigabit 网络连接的独立集群:一个用于运行 Kubernetes 的计算集群和一个用于托管 HDFS 的存储集群。查询 44 大部分执行时间花在三个 Map Vertex 上(Map 2、Map 5 和 Map 7,下面的 MR3-UI 截图中的红色圆圈):
在第一次运行时,LLAP I/O 的缓存为空,三个 Map Vertex 从 HDFS 读取 80.3GB 数据(Scheme: HDFS 中的 BYTES_READ),这些数据都是从存储集群的本地磁盘读取,然后通过网络传输到计算集群。
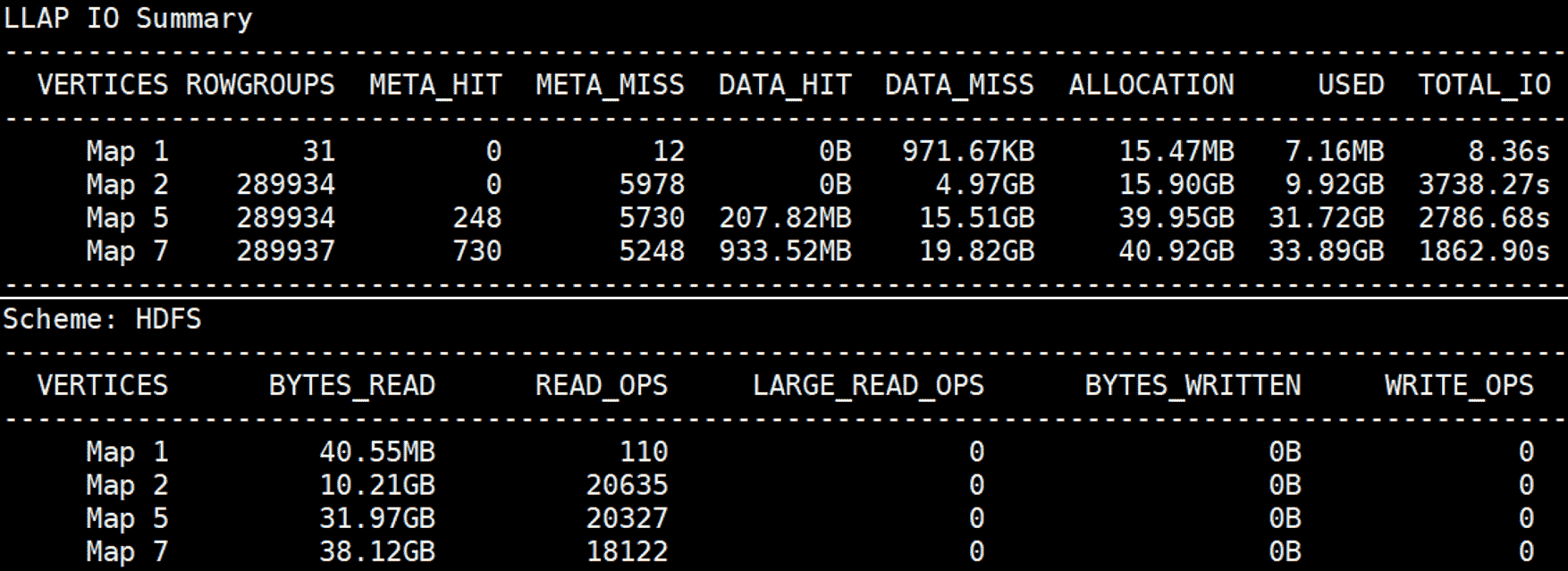
几次运行后,缓存中填充了输入数据,三个 Map Vertex 仅从 HDFS 读取 1.96GB 数据(Scheme: HDFS 中的 BYTES_READ),而大部分输入数据直接由 LLAP I/O 提供(LLAP IO Summary 中的 DATA_HIT)。因此,我们观察到执行时间显著减少。