自动并行度
Apache Hive 中的自动并行度
Apache Hive 支持自动并行度,该功能通过分析源 Vertex 的输出动态减少 Reduce Vertex 中的 Task 数量。在以下示例中,几个 Reduce Vertex 发现其 Task 数量从 1009 减少到 253:
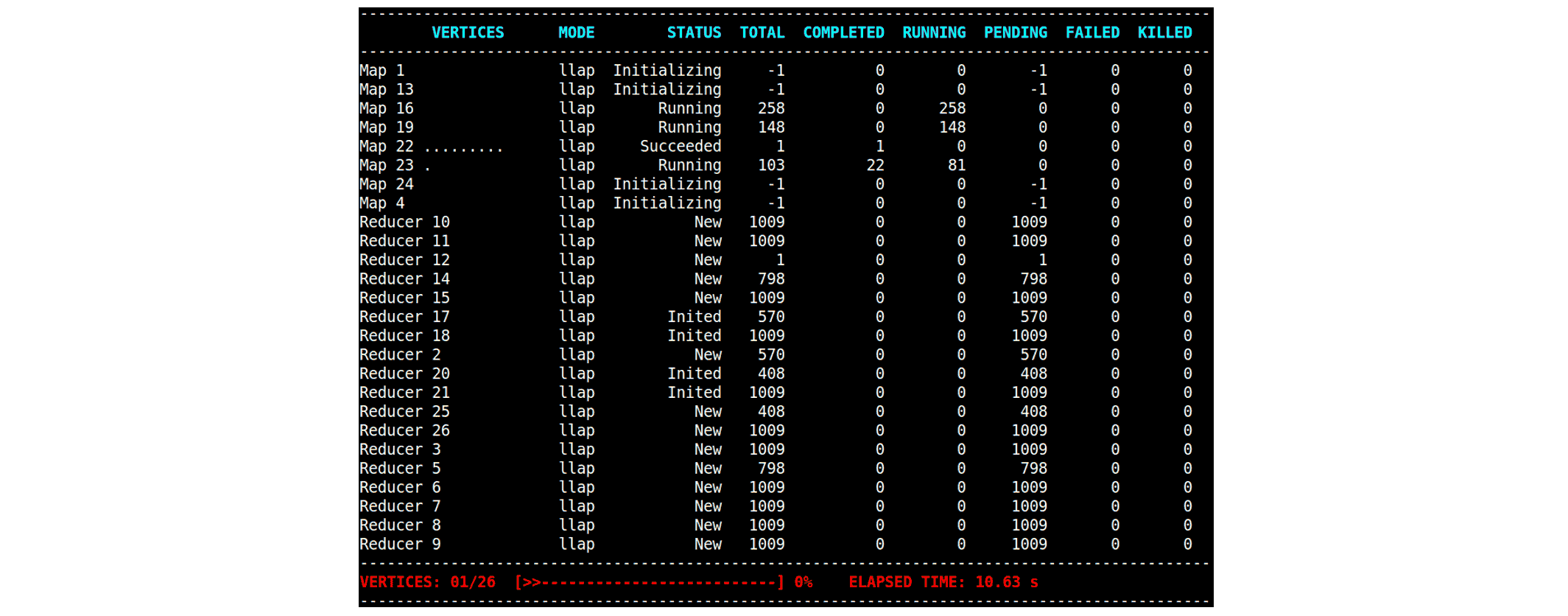
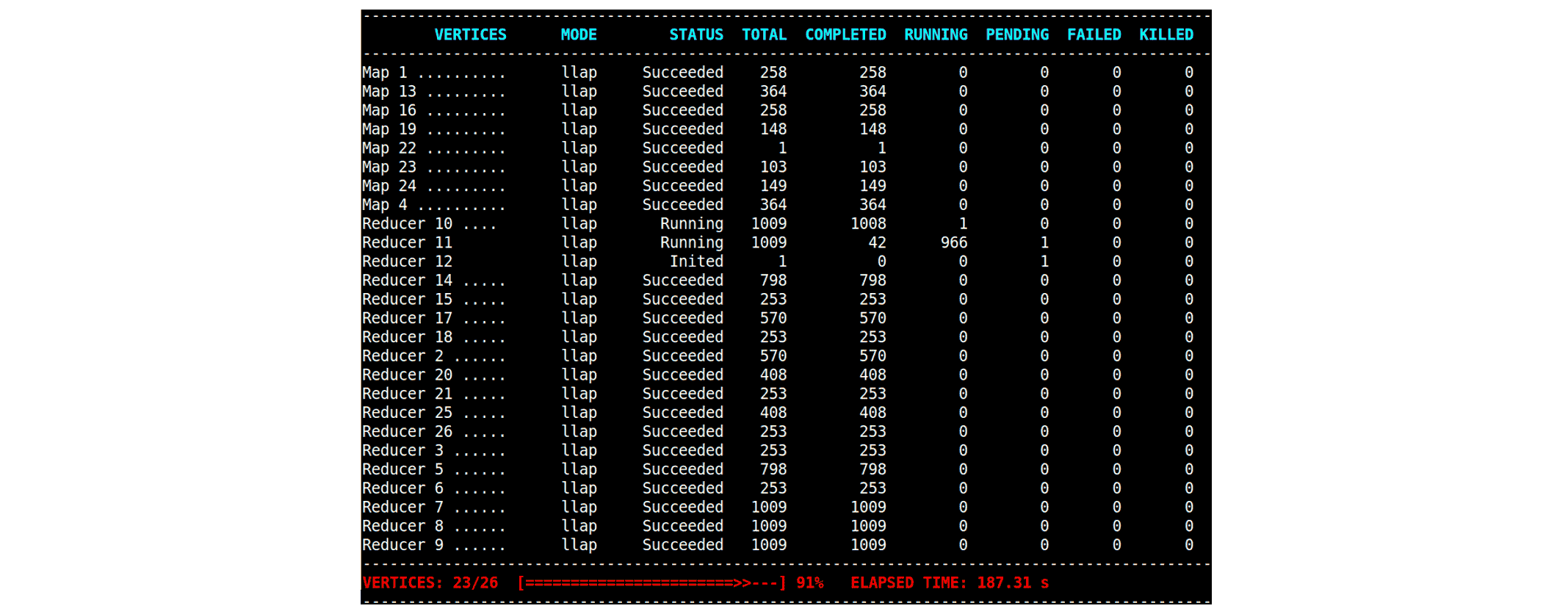
通过为 Reduce Vertex 启动更少的 Task,Hive 能够更好地利用资源,特别是在许多查询竞争资源的并发环境中。此外,启用自动并行度实际上对执行时间没有负面影响。
HivePlus 中的自动并行度
HivePlus 提供了比 Hive on Tez 和 Hive-LLAP 更忠实的自动并行度实现,后两者仅在有限的情况下允许自动并行度。例如,HivePlus 可以对具有 ONE_TO_ONE 入边或出边的 Vertex 应用自动并行度,而 Hive on Tez 和 Hive-LLAP 在应用自动并行度时会跳过此类 Vertex。在下图中,Reducer 7 到 11(绿色矩形中的)都通过 ONE_TO_ONE 边连接,HivePlus 确保在应用自动并行度后它们的 Task 数量保持不变(从 1009 到 253):
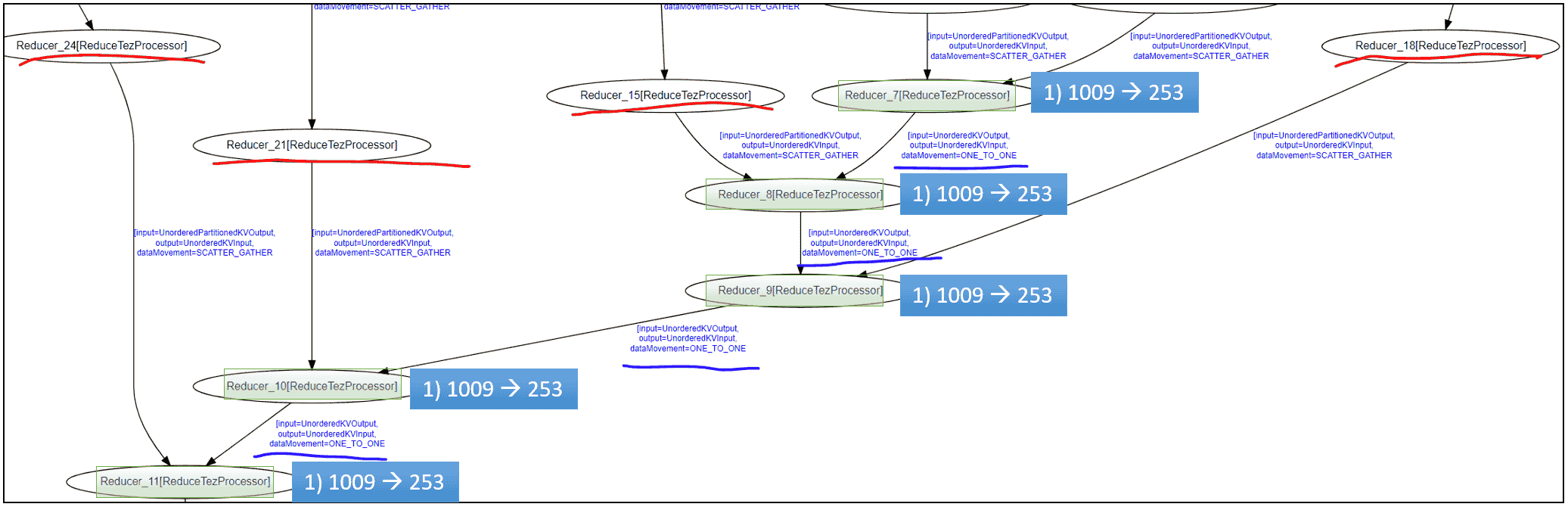
HivePlus 中的自动并行度还允许根据上游 Task 的输出统计信息而不是其 Task 索引将上游 Task 映射到下游 Task(Reduce Vertex 的)。例如,具有小输出的上游 Task 可以被分组映射到单个下游 Task,而具有大输出的上游 Task 可以映射到其自己的唯一下游 Task。通过这种方式,HivePlus 可以减轻上游 Task 输出分布不均的问题。tez-site.xml 中的配置键 tez.shuffle-vertex-manager.use-stats-auto-parallelism 决定了是否分析上游 Task 的输出统计信息。